内存带宽与延迟时间的深入探讨
硬件周刊
对于内存性能的讨论,无不围绕着两个技术名词展开,那就是带宽(bandwidth)和延迟时间(latency)。它们的真正含义到底是什么呢?希望这篇文章能给你一个满意的答案。
一、理论峰值带宽的概念
某些人往往单纯地用数字来衡量内存的总线带宽,他们认为数据通过一条线路传输,传输的速度只取决于传输介质(线路)的质量,每条传输线路都有其固定的传输速率,这样它所能实现的带宽也是固定不变的。
当用这种观点来谈论内存带宽的时候,可能没想过他们所说的带宽只能算是带宽定义的一个方面:理论上的峰值带宽。它的计算非常容易,用固定的公式就可以计算出来(内存带宽=内存运行频率×8Byte(64bit)),丝毫没考虑过数据传输过程中的延迟现象,这种仅仅理论上算出来的带宽在实际应用中是根本无法实现的。所以在带宽定义中还存在着实际应用带宽的概念,它的计算非常复杂,没有固定的计算公式可以表述,因为它和整个内存子系统的各个部分都有着一定的关系,CPU的数据请求状况对它也有着重要的影响。下面先让我们来看看理论峰值带宽计算公式的推导原理。
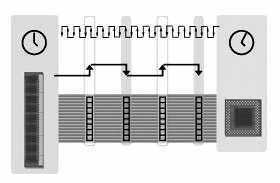
仔细观察上面的内存数据传输示意图(图1),它所表示的是在一个时钟周期内,内存传输4组8Byte的数据给CPU,而每8Byte数据组称为1个word,它是在每个内存脉冲的下降沿传输的。如图1所示的是这种内存在一个时钟周期内可以传输4个word的数据量。目前内存每次读写的位宽均为8Byte,即64bit。假设我们把内存的位宽降为32bit,每个时脉所传输的数据就会变为4Byte(4×8bit)。同理,如果位宽扩展到128bit,则内存的每个时脉所传输的数据将会达到16Byte。
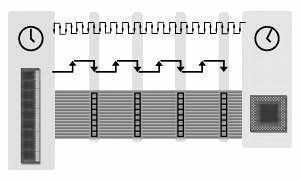
注:数据在内存脉冲下降沿传输的
假设内存的运行频率为100MHz,则它在1秒内所能触发的脉冲就有100×100万个,也就是1秒钟内运行1亿个周期,这样它在1秒内的传输带宽就能用下面的公式来表示:
8Bytes×100MHz=800MB/s
同理,运行频率为133MHz的内存所能达到的带宽:
8Bytes×133MHz=1064MB/s
这两个计算公式计算的都是理论上的峰值带宽,因为它们并没考虑到延迟的问题。
二、实际应用中的延时
在系统中,如果内存直接和CPU相连接,数据使用一个时钟周期在内存和CPU之间传送。在简化的图1中,系统可以连续使用时钟周期来传送数据,但是实际情况并不是如此。CPU发出总线请求命令,接受总线请求的过程都要占用时钟周期。如表1所示:
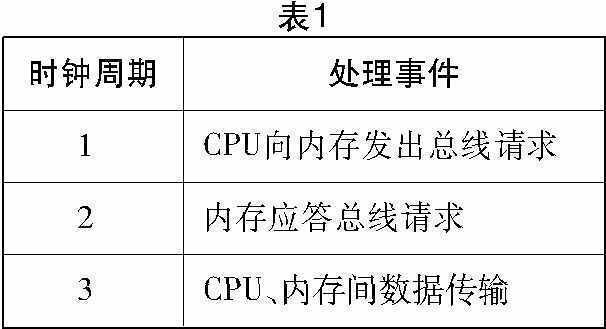
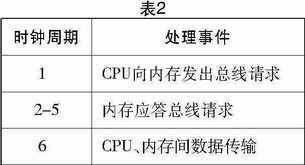
现实中,内存都要使用2-5个时钟周期来“应答”CPU的请求(表2)。
在上面的情况下,CPU和内存直接连接,这主要为了说明简单。但是现实中,CPU和内存一般不是直接连接的。北桥的芯片位于CPU和内存之间,如图2所示。
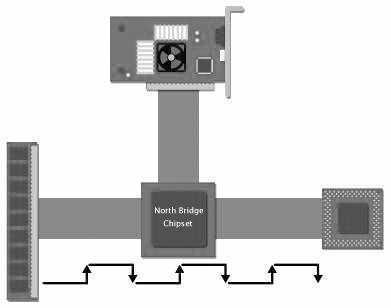
所以内存读的时间又要增加两个时钟周期。一个是CPU发送请求命令到达北桥芯片,另外一个为请求信号从北桥芯片传送到内存芯片。这就意味着系统会使用3个时钟周期来发送,传输“请求”命令;同样“应答”命令从内存返回CPU芯片也要3个时钟周期。
可见,在比较复杂的实际的环境中,内存“读”延时就增加了。而且如果在处理的过程中,有其他设备要使用北桥的话,CPU要使用更长的时间来等待内存的“应答”命令(表3)。
三、实际应用中的带宽
从前面对内存理论峰值带宽的推算中,我们了解了计算任意一款内存最大传输带宽的方法,但这样得出的数值只能作为商家标榜他们的产品性能卓绝的工具,实际应用中的情况呢?
在内存数据传输示意图1中,在每个时钟周期的下降沿都会有8Byte的数据被传到CPU,而内存的运行是持续不断的,数据就会像传送带上的货物源源不断地被传送到CPU,但实际上这条“传送带”上的空间并不是时时被“货物”占用的,这就不可避免地产生了空间浪费的问题,或者称之为无效的带宽。所以理论上计算所得出的结果必然只能适用于理想的范畴。为什么这条“传送带”永远不能装满?因为现今的内存位宽均为8Byte(64bit),这个数值为一个物理BANK,而内存的工作流程决定了在一个脉冲内只能处理一个BANK的数据,所以传送带空间永远装不满。除此之外,北桥芯片的存在,系统的延时(CPU发出数据请求到内存做出反应相隔的时间),内存的运行频率都会影响内存的性能。
前面我们说过了,要计算一款内存的实际应用带宽是很不容易的,因为它没有固定的公式可以套用,而在计算中还必须结合当时使用的系统环境。在CPU发出数据请求通过系统前端总线送达内存的过程中必然要耗费一定的时间,而在内存将数据调取的过程中又会耗去一定的时间,而后把数据通过内存总线与系统前端总线的通路送达CPU时,不耗费时间也是不可能的。这样总的算起来,在整个数据请求(CPU)-发送(FSB)-调取(RAM)-发送(内存总线+FSB)-读取(CPU)的循环过程中要耗费一段并不算短的时间,这一段时间是介于两次数据传输的过程中,这就造成了在这期间内存数据传输的停滞。
这就是内存传输过程中的延迟现象,正是因为这个原因,才导致了内存永远不能以全速传输数据。另外需要说明的是,这种延迟现象所占用的时间往往是非常惊人的,它能达到内存有效传输数据所用时间的好几倍,在这种情况下再来谈论内存的峰值带宽会变得毫无意义。假设CPU想得到100个单位的数据,在数据传输过程中就可能会有300个单位的数据传输时间(有效传输)被占用,这样的浪费在任何高性能的内存使用中都难以避免。
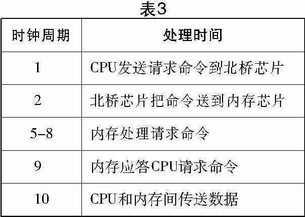
下面的图3就很清楚地展现了在数据传输过程中因为延迟所导致的时钟周期被挤占的现象。
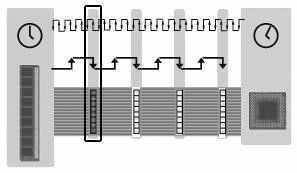
图3中黑框条块表示的是在整个时脉中只有8Byte(1BANK)的数据被有效传输,其他的时间均被延迟所占用了。所传输的数据只占内存整个传输能力的1/4,假设这种内存的理论峰值带宽是1064MB/s,而在实际应用中的带宽却只会有266MB/s。
小知识:我们不妨对内存的延迟类型做一个简单的总结,凡是由系统的总线频率导致的延迟我们就可以把它叫做总线延迟,它的发生主要是在CPU发出数据请求经过北桥芯片到内存DIMM,所调取的数据再从DIMM经过北桥到CPU的整个过程中。另外一种延迟则是由内存芯片对数据处理的速度所决定的,我们可以把它叫做芯片延迟。这两种延迟在计算内存理论峰值带宽时是从来不被提到的,但是它们却对内存的带宽有着至关重要的影响。
四、提高内存带宽的方法
1.更快的总线
增加内存带宽的一种方法是提高总线的处理速度。增加总线的速度使脉冲的周期缩短,脉冲周期缩短后,CPU和内存之间的延时也相应地降低,这意味着在同一个周期内,可以处理更多的命令。所以如果总线的时钟频率增加一倍,内存的理论带宽值也相应地增加一倍。
2.更宽的总线
另一种增加内存带宽的方法是增加总线的带宽。即总线频率不变的条件下(脉冲周期不变),可以在相同的时间内传送多一倍的数据。例如8Byte的总线传输32个Byte的数据要4个总线时钟周期,当总线的带宽增加到16Byte后,只需要2个总线时钟周期就可以把数据传送完毕。
虽然总线带宽加倍,理论上内存的带宽也会增加一倍,但是在实际操作中,效果并不是十分明显。因为总线频率增加一倍,内存读延时会相应降低一半;而总线带宽增加一倍,内存读延时是不变的。所以说,高频率低带宽的总线往往比低频率高带宽的总线处理速度快。
图4就是在这种情况下的比较情况。可见在高频率的带宽下,“紧急数据”(CPU正等待使用的数据,用黑框标出)能够更快地传送到CPU。在系统中,“紧急数据”传送得越快,CPU处理的效率越高。
在某些应用程序中,尤其是多媒体处理,总线要处理大量的流数据,所以“紧急数据”传送得越快,内存工作得越有效。如果在某些应用中,“紧急数据”不是那么明显或者并不很重要时,就可以使用提高总线带宽的方法来提高内存的有效带宽,因为这比提高总线频率的成本更加便宜,更加方便。
3.双倍数据传输速率
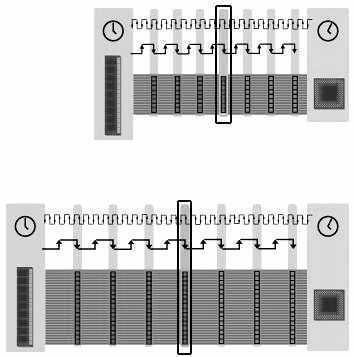
另外一种比较简单的方法是,在时钟的上升沿和下降沿同时处理数据。要比提高总线频率方便得多,这就是我们常说的DDR技术。以下是DDR总线图(图5)。
可以看出:总线能够在上升沿和下降沿处理数据,能够把以往在4个脉冲时间内传送的32Byte在2个脉冲时间内完成。虽然DDR技术使得总线的带宽提高一倍,但是这并不意味内存的性能也提高一倍。
这主要是DDR内存的延时并没有降低,比如,由于200MHz SDR的延时时间是100MHz DDR的一半,二者比较,CPU处理“紧急速据”的时间并没有缩短。
注:上为DDR总线,下为SDR总线
如图6所示,DDR总线比SDR总线在相同时间内多了4个脉冲周期,但是“紧急数据”传输(图中黑框标出)和SDR总线的到达的时间是相同的。
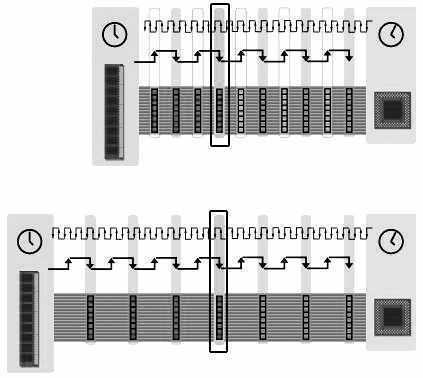
虽然DDR技术使内存理论带宽增加了一倍,但在某些方面还是有缺陷的。所以一个理想的增加内存带宽的方法是同时增加总线的频率和降低内存的访问延时。
结论
在某些情况下,非数据总线冲突(地址总线访问冲突,控制总线冲突等),也会影响内存的带宽。而且在简单的总线结构中,地址总线冲突和控制总线冲突,会大大降低总线的有效带宽,因此影响内存的带宽。所以影响内存带宽的因素还有很多,在此就不一一详述了。希望阅读完此文后,读者能够对内存的延迟和带宽有个深入的认识。