利用数字技术的激光唱片(CD)已问世十多年,它以优质声音和快速选曲等突出优点,使利用模拟技术的密纹唱片渐趋淘汰。
CD的取样频率为44.1kHz、量化比特数为16,因而码率为44.1k×16≈705kb/s。由于记录的是立体声,信息量应取为这一数值的两倍,即约为每秒140万比特。
磁带或唱片上能够记录的信息量是与记录媒体的面积成正比的。直径12cm的CD上能记录信息的时间约为74分钟。
为了在DCC(数字盒式磁带录音机)、MD(微型唱片)之类的小面积录音媒体上记录较长时间的信息,必须采用提高记录密度或减少信息量的方法。从技术和费用等方面综合考虑,以采用减少记录信息量的方法为好。因此,大多采用在压缩信息量,使在不改变记录在媒体上数据量的情况下,延长记录时间。
在实际中,当使用数字压缩技术以后,已可使经过压缩后的声音与未经压缩的声音,听起来无任何差别。
在数字音频技术中所使用的压缩技术大致可分为两类:一类是利用声音信号本身所具有的性质;另一类是利用人耳听觉特性。
一、利用声音信号本身性质进行压缩
图1所示为钢琴声的波形,信号的声压级变化较大。如对它进行A/D(模/数)转换,信息量将很大,即在变换为数字信号时,需将变换的时间间隔取得短些(即取样频率要高,例如48kHz),并将幅度电平分得很细(即量化比特数要多,例如16比特。
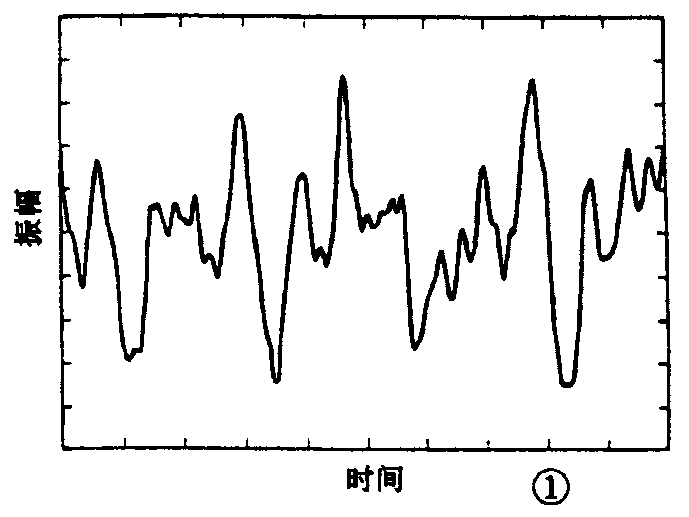
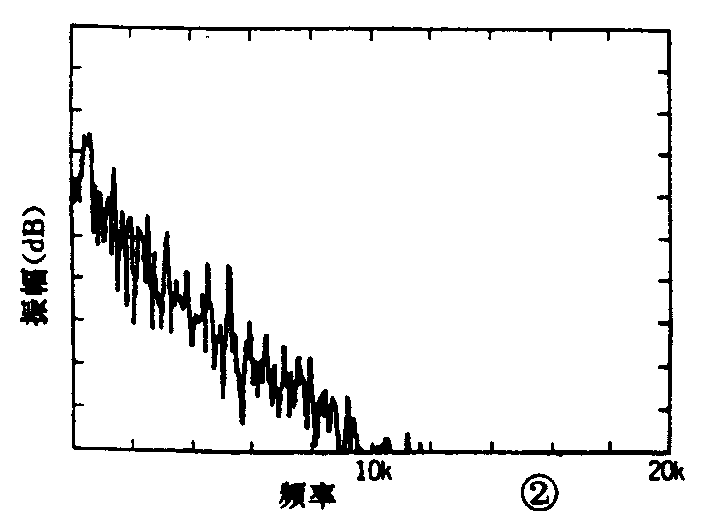
图1波形的频谱图如图2所示。可以看出,所有频率成分明显地集中在10kHz以下区域内。通常,人的讲话声、音乐声和自然界的声音都有向低频方面集中的倾向。利用这种性质,就可以考虑对信号的幅度进行较粗的量化来减少比特数,以及减低取样频率来压缩信息量。再进一步,还可采用将频谱中幅度小的频段减少量化比特数;在无频谱的范围将数据予以省略的方法。利用以上方法后,信息量约可压缩到1/2~1/3左右。
二、利用人耳听觉特性进行压缩
进一步研究减少信息量的方法时,可以再考虑一下人耳对图2中的所有频谱是否都能听到。对于听不到的部分,是否可将它省略掉。
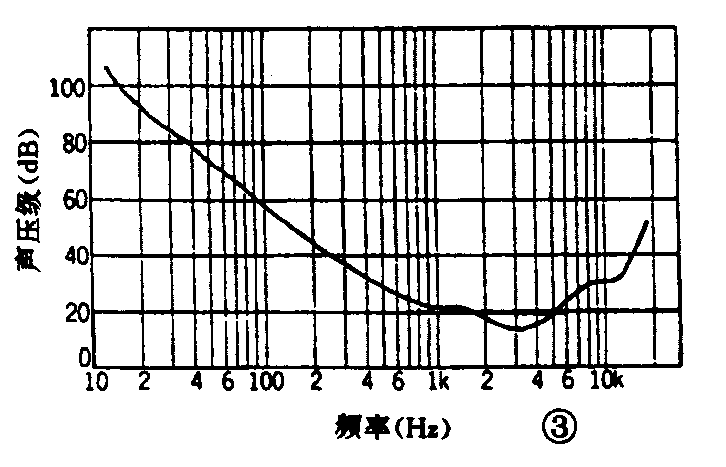
研究人耳听觉特性可知,人耳感受声音灵敏度最高的频率约在2~3kHz附近。以它为基准,可将人耳对各频率声音所能听到的最小声压级绘出,如图3所示,称为听阈曲线。即人耳不能听到的小于曲线声压级的声音,在记录或传输声音时,可将这些声音省略掉。也就是说,可以减少记录或传输声音的信息量。特别是高频成分声音的听阈较高,因而可以对它进行较粗的量化,也就是可以用较少的量化比特数来量化,从而减少信息量。
另外,压缩信息量还可借助于人耳听觉特性中的掩蔽效应。人们在街上谈话时,当卡车通过的瞬间,会听不到对方的谈话声,这就是由于卡车声掩蔽了谈话声。图4所示为不同声压级1000Hz声音对其它频率声音的掩蔽曲线图。
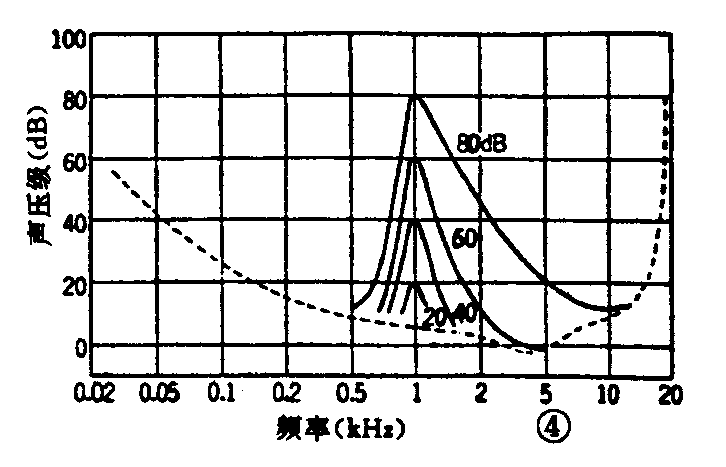
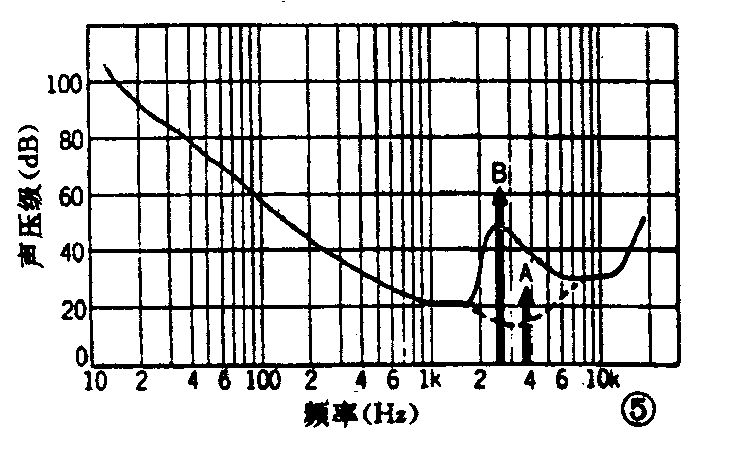
图5所示的虚线部分为原来的听阈曲线,当有A频谱声音时,由于它大于听阈曲线,人能听到它。但当同时出现有图中B所示的大声压级声音时,听阈曲线将改变如图中实线所示。因而由于有B声音存在,使A声音不能被听到。即当同时存在AB两个声音时,A声音将会听不到,所以可将它省略掉。这样,利用人耳听觉特性,在不改变实际能听到的声音的情况下,可将原来的声音信号的信息量压缩到1/4~1/6。
三、如何进行压缩
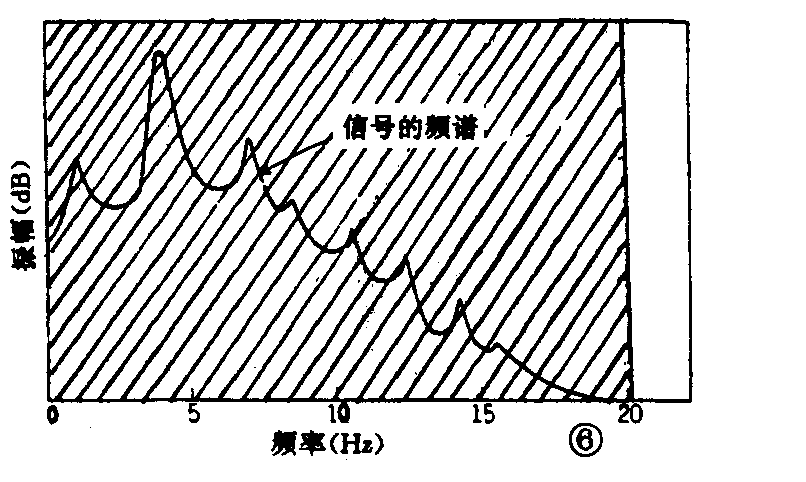
图6所示为未压缩状态下的信号频谱。这种状态就是将模拟信号经A/D转换后成为数字信号的状态。例如以取样频率48kHz、16比特量化时的情形。信号的信息量相当图中斜线所示部分,即未压缩状态如图中长方形所示。
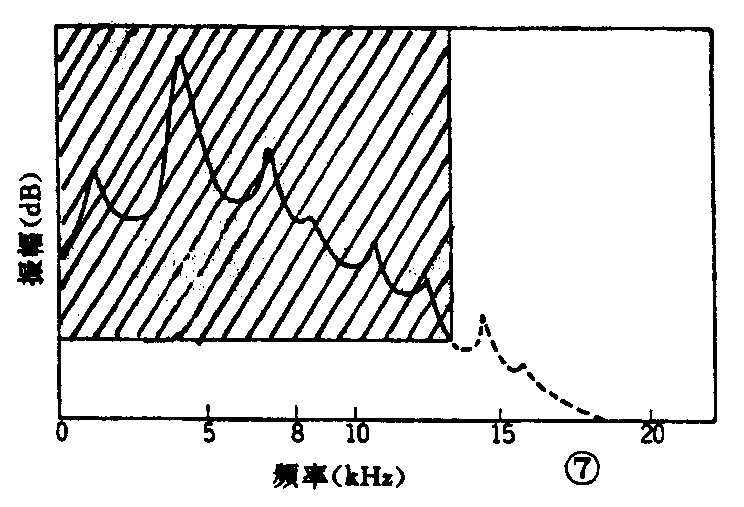
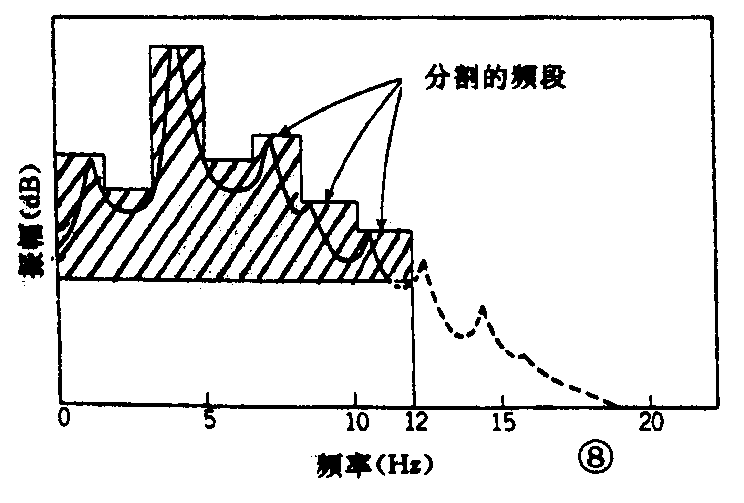
另外,利用声音信号本身性质进行压缩的频谱如图7及图8所示。图7为以小的量化比特数和低取样频率变换的情况。图8为将信号以适当的频带宽度分割,以每个频带相适应的频谱成分分配量化比特数,即改变与每个频带最大声压级的成分相适应的量化比特数,使动态范围随分割后的每个频带而变化。结果,信息量可压缩成如图8中斜线部分所示。
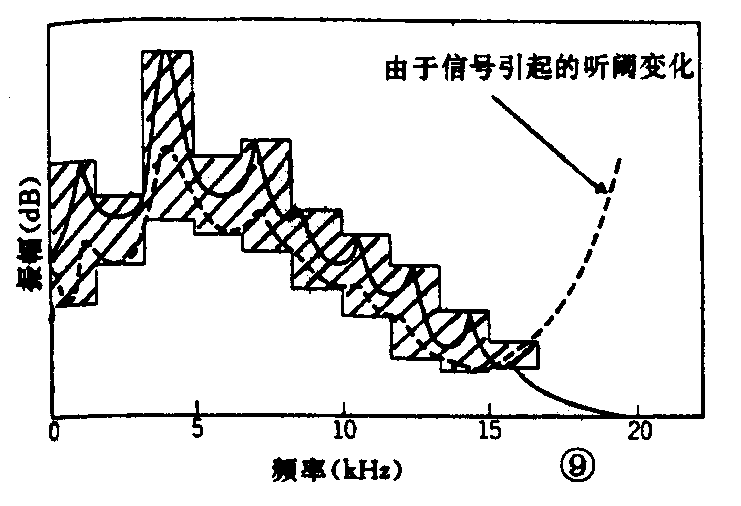
如果再考虑利用人耳的听觉特性进行压缩,则由于信号频谱所产生的掩蔽效应,使听阈曲线成为图9中虚线所示。与图3中的听阈曲线对比可知,一些幅度较大的信号也变得听不见了。于是,信息量被压缩为图9中斜线部分的面积。将它与图6~图8中斜线部分面积相比较可以看出,信息量又有很大的压缩。
以上介绍了DCC、MD等进行声音信号信息量压缩的基本概念。具体压缩时,对频率处理的方式有利用频带滤波器的,也有利用付里叶变换的,并且对掩蔽的听阈的计算方法也有所不同,因而产生了各自不同的压缩方法。DCC采用精确自适应子频带编码(PASC),将信息量压缩到原来的1/4;MD采用自适应变换听觉编码(ATRAC),将信息量压缩到原来的1/5。(张绍高)