文字识别,就是用计算机自动认识印刷或手写的文字,它属于文字信息处理技术的研究范畴,与人工能技术和图象处理技术密切相关。
文字识别主要包括光学特征识别(OCR)、光学特征处理和电磁特征处理3部分,但识别的研究工作更侧重于前者。因此,文字识别一般即指光学特征识别。OCR研究工作的主要分支有:
1.印刷体文字识别。指的是识别特定的字体或打印的文字。
2.在线文字识别。指的是针对单一的手写体文字的识别,在这种情况下,不仅可以利用文字的图象信息,而且可以获得每个笔划的实时信息。
3.手写印刷体文字的识别。指的是针对单一的手写体字集中文字的识别,且字集中的文字互相没有联系,并且书写时有严格的限制。
4.手写体文字识别。指的是对无限制的手写体文字的识别,文字的书写没有严格的限制,并且文字之间可以存在着联系。
因此,根据识别技术的难易程度,可以把文字识别分为(从最困难的领域开始):手写体文字识别,手写印刷体文字识别,在线文字识别,印刷文字识别和电磁、机械转换5大领域。
在设计文字自动识别系统时,为了缩短识别时间,提高识别精度,通常采用多级识别方法和系统。也就是说,先根据宏观特征、整体特征将文字进行分类,然后根据微观特征、局部特征进行识别,或者前面一级或几级先用较简单的方法和分类器识别较简单的文字图象,后面一级或几级再用较复杂、完善的方法和分类器识别较难识别的文字图象。其总体框图见如左图所示。
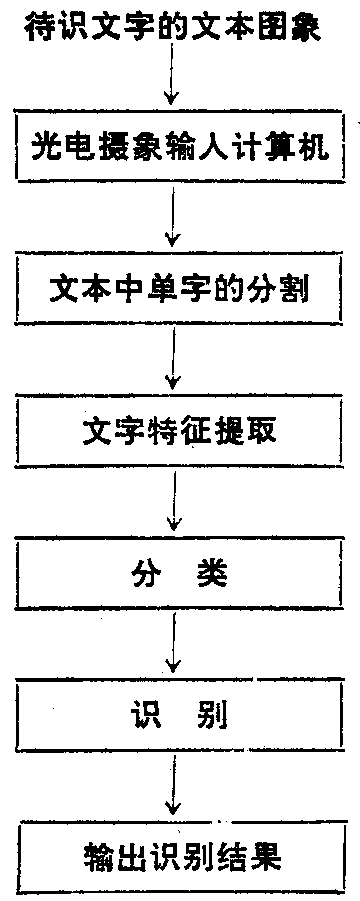
文字识别系统中常用的光电摄象输入设备有:分列扫描器、机械扫描器、激光扫描器、飞点扫描器、光电摄象管和感光单元矩阵扫描器,而对于在线文字识别,可以采用计算机书写板直接输入文字。
文本中单字的分割、特征提取、分类和识别4大环节是由计算机完成的,因此文字自动识别系统运行的速度,在很大程度上决定于处理软件优化的程度,它与分类识别方法密切相关。常用的分类识别方法有:
1.点到点的匹配方法。即存储的文字特征模板的所有象素和文字图象的所有象素进行一一比较。
2.总体变换方法。如R-L变换、付里叶变换以及转动惯量转换等。
3.抽取位置特征方法。位置的特征是指端点、交点、拐点和支点等,这种特征提取可采用许多方法来完成,如模板匹配,但通常必须先对文字进行预处理。
4.抽取笔划特征方法。这种笔划特征可以是相互垂直的,也可以仅仅是垂直或水平方向的。
5.曲率分析方法。这包括曲线跟踪,凹面的检测和几何分析。
6.结构方法。这种方法包括把文字分解成基元、进行拓扑结构描述,并组成图表。
系统中计算机主机(IBM-PC及其兼容机)和输入、输出设备之间的数据通信是由计算机视觉接口板来完成的。
目前,文字识别技术主要应用在以下几个方面:
●数据输入(银行系统) 在这个应用领域中,文字集的数量是很有限的(数字和一些特殊符号),同时纸张格式受到严格的限制,但处理的数据量很大。这种阅读机的处理速度(通常包括分类时间),为每秒3000个字符,误识率为0.01%。
●文本输入(办公自动化)办公自动化包括了大量的信息处理过程和技术,今天的文字识别已由广泛的研究变为主要针对办公自动化。这种文本输入阅读机通常处理普通纸张和格式的文件,如用于新闻出版业以及政府机关。在严格限制操作环境的条件下,误识率为0.01%,拒识率为0.1%。
●自动处理(邮件分拣)文字识别技术现已应用在邮件自动分拣中,即自动阅读信件地址。这里所考虑的不是阅读的精确程度,而是通过控制某些过程,使邮件得到正确分类。这种阅读机的处理速度为每秒500个字符,可接受的识别率为80%以上。
●盲人阅读机 文字识别的一个重要应用是为盲人服务。盲人阅读机装有语音合成系统,可将识别出的文字变为声音,以便使盲人“阅读”文件或书籍。
由此可见,文字识别有着广泛的应用前景和实际意义。人们已经开发出了能识别英文(拉丁)、日文、俄文、阿拉伯文、希腊文的系统。对于汉字的识别也已取得了可喜的成果,但迄今仍无商品问世。这主要是由于识别速度不高,识别率不高,且价格昂贵。由于汉字字形繁多,结构复杂,使得汉字识别的工作十分繁重,因此汉字识别必须根据自身的特点,与人工智能、专家系统、计算机科学、数据库理论、模糊数学、图论等学科相结合,开发具有自己特色的特征抽取和识别方法。汉字识别所带来的汉字输入手段的革命,必将使程序员从繁重的键盘输入工作中解放出来;彻底解决汉字的输入速度远低于计算机运行速度和输出速度的问题,大大提高中文信息处理的自动化水平。(唐松 肖谷)