(温宪立)汉字信息处理技术是为了解决计算机处理汉字问题而发展起来的一门新技术。近年来,国内外汉字信息处理技术发展极为迅速,各种类型的汉字信息系统不断出现。无论是单用户、多用户汉字信息处理系统都要涉及到汉字的输入问题。
从现阶段看来,汉字的输入可以分为两类:一类是键盘输入方式,另一类是自动输入方式如图1所示。自动输入方式涉及到语音和字形的识别问题。主要是地方音和手写体的识别。具有一定的难度。现在汉字的输入主要采用键盘输入方式,这种方式又有以下几种。
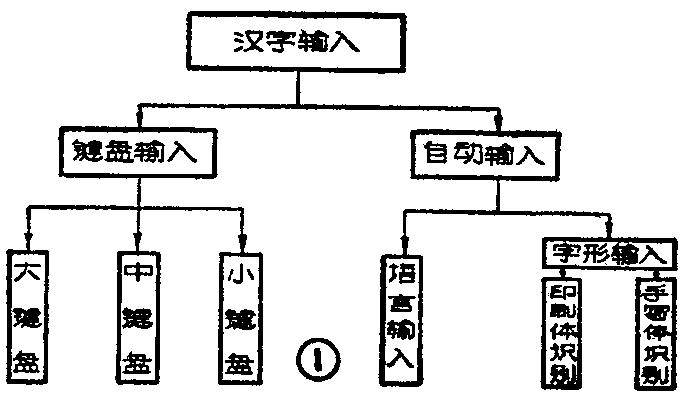
(一)大键盘输入:当前使用的大键盘,主要是笔触式大键盘。这种大键盘的盘面上有3000多个汉字,包括常用字和非常用字。它是利用一支带开关的笔,接触盘面上的汉字,并按动笔上的开关,以选通这个汉字的X,Y坐标,产生这个汉字的坐标码,再将这一点的坐标码转换成对应于这个汉字的二进制代码。这种输入方式,操作方便,使用前不需要进行专门训练,也不需要记忆编码规则,只要认识汉字的人,稍加学习就可以操作。但一般说来,大键盘找字比较困难。
(二)中键盘输入:中键盘一般用汉字构件做键,然后用拼接的方式进行组合,得到所需的汉字。这种键盘,键数在200~400之间,由于采用了拼接的方法输入汉字,比较适合中国人用偏旁部首查字的习惯,训练容易。缺点是训练时要分清上下拼、左右拼,及混合拼。另外,由于构件的分解度没有统一标准。所以中键盘的键数也没有统一标准,不利于做成标准化产品。
(三)小键盘输入:小键盘就是采用西文计算机上使用的标准ASCII键盘。利用小键盘输入汉字,要涉及到编码方案问题。现在主要有“见字认码”,“纯字形编码”,“声形结合编码”,“笔形编码法”,“三角编码”等输入编码方案。一个好的编码方案,应该是:规则简单;易学易记;重码率低(所谓重码是指按照编码规则,一个编码对应二个以上的汉字);码子短,击键次数少等。小键盘输入方式,便于操作员“盲打”,输入速度比较快,但操作员要熟记编码规则,就是给每一个汉字对应一个数字串或符号串。近几年来,国内外许多科学工作者对此作了专门的研究和探讨,提供了近450种汉字编码方案。这些编码方案大致有以下几种:
1、国家标准编码(GB2312—80)国家标准码也叫作信息交换用汉字编码字符集。该标准规定了汉字信息交换用的基本图形字符二进制编码表示法。共收集汉字6763个。分两级,一级汉字3755个,二级汉字3008个。按部首排序。还有一般符号202个,序号60个,数字22个,拉丁字母52个,假名169个,希腊字母48个,俄文字母66个,汉语拼音符号26个,汉字注音字母37个,连同汉字共有为7445个。
标准编码与汉字有确切的一一对应关系,是交换汉字信息的法定标准。但是这种电码与电报码相仿,与汉字的属性缺少有机的联系,因而很难记忆,一般不适应作为输入编码。
2、形码:由于字形不受方言的影响,是有利于汉字输入的条件之一。形码又分为笔形码和字形码。前者是按一定顺序读取字的基本笔划后者则把汉字分解为若干基本部件(或称构件、字根、字元)按一定方式进行拼装。如图2所示。

3、音码:音码就是利用汉语拼音输入汉字。由于汉语拼音存在一音多意的问题,所以在音码中把汉字可做为词组处理。输入词组的第一个字的拼音时,可能出现所需的同音字,但是接着键入第二个字的拼音后,就会自动修改第一个字。保证前后的字具有一定的关系。
4、音形码:音形码是在汉语拼音的基础上,加上字形信息,就构形了音形码。音形码首先利用拼音,其次利用字形信息来区分一词多义。
(四)字形识别输入:汉字字形识别输入是人工智能模式的一种。它能够自动、高速地输入汉字,是计算机输入汉字的一种较好的手段。字形识别可分为印刷体识别和手写体识别两类。
1、印刷体识别:在识别印刷体时,首先要对输入的原稿用光学的方法进行检测。将文字信息转换成电信号。主要用飞点扫描法,光电摄象法、光敏矩阵法、激光扫描法等。然后对原稿进行分类、判别。识别过程如图三所示。

2、手写体的识别:手写体识别可分为在线和脱线手写体两种。在线手写体汉字的识别是由计算机跟踪图形输入板上移动的笔尖,并通过对笔尖的运动轨迹做出分析,待书写完某一笔划后,立即产生一个标志,表示该笔划结束,立即进行识别,这时必须对信号进行预处理,以便消除笔尖在图形输入板上书写时产生的噪声及冗余信息。脱线手写体识别一般都采用结构分析法,即把汉字看作二维空间的图形。这样就有许多结构(如边旁)可以共享。然后利用组装拼合的方法来识别汉字。现在识别主要的问题是识别率和识别速度问题。现阶段识别率不可能达到100%。有待于进一步研究。
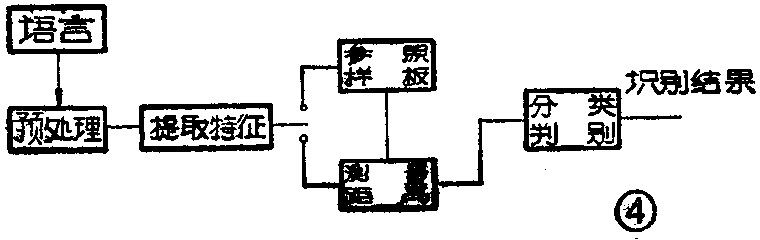
(五)语音输入:利用语音直接输入汉字,是一种最自然的输入方式。最初的语音识别输入系统对输入者有许多限制,如:限制说话的人和说话方式,限定词汇量,单词间要有休止间隔等,也就是说与说话人有关。现在语音识别已经取得了一些发展,可以使上述各种限制减少许多,可以做到与讲话者无关。但是,概括起来,语音识别系统都是由语声分析和模式识别两部分组成。语声分析又包括预处理和特征提取两部分;模式识别包括测距和分类。语言识别系统如图4所示。语音识别和汉字的字形识别一样,有许多课题还需要进一步探讨研究。