邮电通信好比是国家的神经系统,它能沟通国内外各方面的联系,其中信函又是人们最常用的通信方法。

一封信从投入信箱到送达收信人手中,概括来说,要经过收寄、分拣、运输、投递几个环节,如图1所示。其中分拣与运输都是重复进行的,尤其是分拣,次数最多、工作量很大。长期以来,分拣工作基本上是人工操作的,不仅效率低,而且劳动强度大。分拣工人眼看——阅读信封上的地址;脑想——确定寄达局和经转路线;手送——将信投入相应的贮信格子里。一个工人平均每小时只能分拣一千余件。
广大邮电工人迫切要求实现信函分拣自动化,以代替繁重的人工操作。
怎样实现信函自动分拣
实现信函分拣自动化,首先必须实现机器对信封上书写的收信人地址的自动识别。从目前科学技术水平看来,对手写汉字的自动识别还很困难,而对手写阿拉伯数字的自动识别已是可能的了。因此用阿拉伯数字在信封上书写收信地点的邮政编码,就为机器识别收信人地址,完成自动分拣,创造了条件。
人要识字,首先必须通过眼睛将看到的图形反映给大脑,大脑才能判断这是一个什么字。要机器自动识别数字,也得先将数字图形的光学信息转换为电子信息,使机器完成某些特定动作,即完成识别功能。这种信息转换工作技术上称为“光电转换”。光电转换的方法很多,下面简单介绍一种“飞点扫描”法。

假设“2”这个阿拉伯数字写在一块10×10平方毫米的方块内,如图2所示。我们可将这10×10平方毫米的小块分成100个1×1平方毫米的小方块,并把每个小方块看成一个点。所谓飞点扫描就是利用一个特别的光源,发出一个受电磁场控制产生偏转的聚焦光束,而且这个光束可灵活地在数字区域上进行扫描,从上到下,从左到右依次照射数字区域的每个点。实际上信封是放在传送带上的,被照射的数字区域借传送带作用作水平方向移动,因此只要求聚焦光束作上下扫描运动就行了。如果我们假设一毫秒时间内聚焦光束从上到下依次照射十个小点,而数字区域每毫秒水平移动1毫米,那么,经过10毫秒时间后,聚焦光束就依次照亮了100个小点,完成了对10×10平方毫米数字区域的全部扫描工作。
在上述扫描过程的同时,我们利用一种特殊的光敏器件接收从数字区域反射出来的光线。所谓数字区域就是写着数字的那一块纸,从这块纸的不同部位反射出来的光线是不一样的。无字迹的部位反射光强,有字迹的部位反射光要弱得多。光敏器件就是根据反射光线的强弱不同而输出大小不同的电信息。因为在扫描过程中已把10×10平方毫米的数字区域当作100个1×1平方毫米的点,所以,光敏器件输出的信息是与100个光学小点所对应的100个电脉冲,每个信息的大小与它相对应的点明暗程度有关。
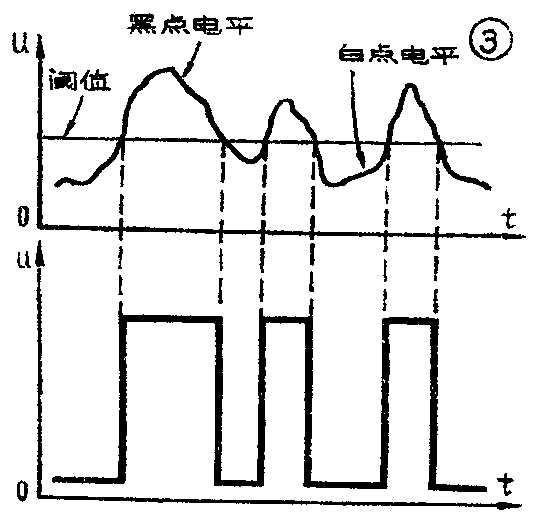
由于纸张质量不同,字迹深浅不一,以及某些点正好位于文字笔划的边缘,一半黑一半白,产生了灰色现象,所以上述光电转换后得到的电信息是连续变化的模拟信息,如图3(a)所示。这种信息不适于直接用来识别,还必须作一定的技术处理,经过门限电压(即阈值)的筛取,成为如图3(b)所示的或是“1”、或是“0”的二进制数字电信息。这一工作,技术上称为“正量”。把正量后的100个串行的二进制数字电信息送入一个由10×10共100个单元组成的矩形点阵形式的电子存贮器中,然后再通过一定的技术处理,使存放在矩形存贮器中的电信息与原数字区域的光学信息在位置上相对应,这样,矩形存贮器中就有一个用电子信息写的“2”字。但是人们所用的书写工具有区别,各人书写习惯也有差异,因此手写数字的笔划有粗有细,字体有大有小。在这种情况下,为了便于机器正确识别,还必须对存贮器内的电信息进行一次技术处理,使字体的笔划粗细、字体大小规格化,并使其字形特征显露出来;这一工作技术上称为“予处理”。
最后就要进行对被识别数字的判断工作了。这好象是人眼看到字形后,由大脑来判断出这是一个什么字。这一工作一般都是由一台专用计算机来完成。
人们从10个手写阿拉伯数字各种字形的笔划分析中得知,对每个数字来说,不管写法有何变化,构成这一数字的笔划图形总是具备一些代表这一数字而区别于其它数字的特征规律。例如“2”字,它有两个端点,从起笔端点开始笔划总是向右方或是右上方或是右下方延伸,并数次改变方向,最后又是向右或右上方或右下方至收笔端点为止,它还一定有一个向右、一个向左的凹凸形变化的线段。如果把“2”字写成图2中所示的形状,它除了具备上述特征外,还多了一个闭合环和一个四节点(即笔划交叉点)。这些就是2的特征规律,其它的数字可能复杂或简单一点,但都能找出它们各自的特征规律。
人们根据大量分析的结果,制定出分别代表十个数字的各条笔划特征规律的顺序逻辑。有的数字有几种写法,例如刚才提到的“2”字,于是可以制定出几条相应的特征规律顺序逻辑。把这样制定出来的几十条顺序逻辑转译成二进制数字电信息存入计算机的主存贮器内。识别时,计算机用一条专用电路对被识数字的笔划特征进行逻辑分析,以确定笔划的延伸方向、凹凸现象、端点位置等,同时与主存贮器中存放着的几十条顺序逻辑相比较,如与其中某一条顺序逻辑全部符合,则被识数字就被判断为那条顺序逻辑所代表的阿拉伯数字了。文字就自动识出。一个字识出后,先把它寄存起来。等所填的邮政编码的几个数字全部识出后,就知道了这封信的寄达地址,再取出这些电信号,驱动有关机构,使信件自动落入相应的贮信格子里。
如果寄信人在填写邮政编码时写了一个谁都不认识的怪字,计算机对这怪字的笔划特征进行逻辑分析后,与所有的顺序逻辑相比较,结果都不符合,这时机器就拒绝识别,将该信剔出。所以大家书写邮政编码时要注意笔划端正、不连笔、不涂改、不写怪字、不要填出了格子。
实现信函自动分拣还要有一条完整的自动化流水线,在信函识别前要完成分类、整理、盖销工作,分拣后要完成捆扎入袋等工作,这里就不一一作介绍了。
邮政编码及其意义
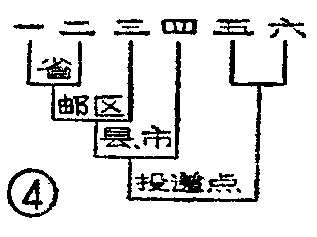

邮政编码是由数字组成的邮局及其投递区域的代号,是按照邮件的经转关系和寄达局的地址编列的。我们国家的邮政编码是由六位十进制数字组成的。编码的六位数相互关系如图4所示:前二位表示省、市、自治区;前三位表示邮区;前四位表示县、市局;后二位表示投递点。例如一封从沈阳寄出的信如图5所示,信封左上角写着邮政编码201708,表明寄达局是上海青浦县华潮邮电所。其中前二位20表示上海市;前三位201表示上海市郊区;前四位2017表示青浦县;08表示华潮邮电所。值得注意的是,邮政编码只代表邮政投递区域的范围,而没有包括收信人的具体街道、门牌号。所以,在信封上除了写明邮政编码外,仍要写清收信人的详细地址,才能保证投递员将信准确送到收信人手中。
信函分拣自动化的实现和电子计算机技术在邮政通信部门的应用,必将引起一场技术上、组织上的重大改革。实行邮政编码制度,既是技术改革的需要,也是组织改革的先行。
实行邮政编码是在目前技术条件下解决机械自动识别的主要途径,是简化分拣工作的重要措施,是广大邮政职工的迫切愿望。实行邮政编码符合邮政科学技术发展方向。它不仅可以解决信函自动分拣问题,随着邮政技术的进一步发展,将对报刊、包裹、汇票乃至一切邮件的自动处理发挥作用。同时,由于分拣中心局的建立,邮件的经转关系相对固定,为机械集中作业提供了条件,对加速邮件传递,确保邮件的及时性,特别是对战备通信有着更为重要的意义。
总而言之,实行邮政编码,是一个关系到尽快建成一个快速、高效、平战结合的现代化通信网,实现邮电通信现代化的大事情。我们每一个同志都应积极采用、热情宣传邮政编码,切不可等闲视之!(方人)