Intel的新武器——Intel下一代处理器架构分析(下)
技术大讲堂
随着贝瑞特的当众一跪,“NetBurst架构可以让CPU的工作频率提高到10GHz以上”的预言也终于在3.8GHz前画上了句号。在双核处理器没有达到预期效果的尴尬情况下,为了改变当前的被动局面,Intel在2005秋季IDF(英特尔开发者论坛)上作出了重大决定,将对桌面平台、移动平台和服务器平台处理器进行架构上的统一,推出全新的处理器架构!
Parrot架构的优势在哪里
与Pentium M架构一样,Parrot(Power—Aware aRchitecture Running Optimized Traces)架构也是由Intel在以色列海尔法的微处理器实验室所提出的。整个架构的设计思路源自著名的“阿姆达尔”法则(Amdahl'Law),该法则的关键点是“在计算机编程的并行处理程序中,少数必须顺序执行的指令是影响性能的一个要素,即使增加新的处理器也不能改善运行速度”。基于阿姆达尔法则,研究人员发现多核心设计并不是改善处理器效能的万能武器,因为对于必须顺序执行的指令,再多的处理器都无济于事。因此,优化处理器的执行结构便成为提升顺序指令的唯一方法。
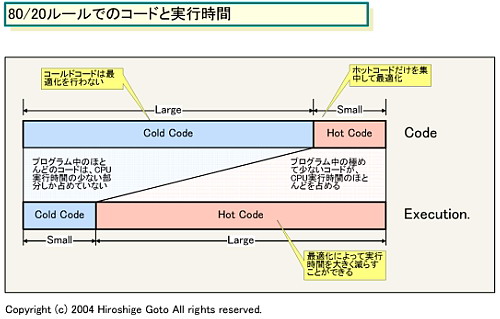
研究人员通过大量的测试及分析发现,处理器在处理任务时,程序中的顺序执行指令虽然只占20%的比例,但这些指令会让CPU前端解码器和后端动态执行调度单元频繁地传输相同的代码和重复执行相同的指令,CPU动态资源的80%都被这种顺序指令所占据!在这个过程中,CPU消耗了大量电力却没有获得应有的效能。正因为如此,RISC(Reduced Instruction Set Computer,精简指令系统计算)指令体系开始盛行。凭借指令高度简约、晶体管规模较小、运行性能较高等特性,RISC指令体系在高端服务器领域迅速取代了CISC(复杂指令系统计算)的主流地位。同时,人们还将服务器RISC体系中先进的技术引入民用x86架构,以提高PC处理器的性能,例如我们常说的EV6总线、整合内存控制器、Hyper Threading技术、双核心架构等等,都是其中的典型代表。
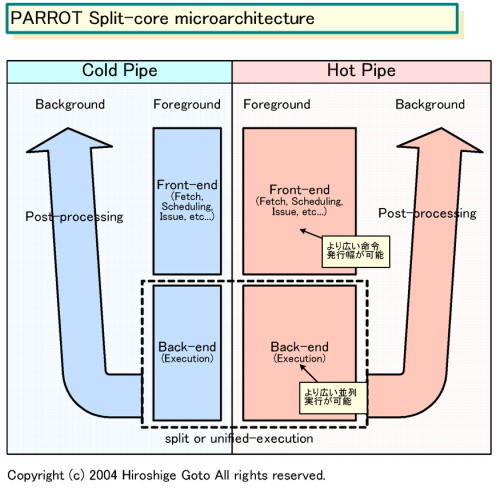
在Parrot架构设计中,研究人员将20%顺序执行指令定义为“热代码(Hot Code)”,而剩下的80%乱序执行指令则定义为“冷代码(Cold Code)”。这样一来,处理器中的逻辑运算单元也就对应地被划分为了“热核(Hot Spot)”和“冷核(Cold Spot)”两部分,而处理器执行管线则分别为“热管线(Hot Pipe)”和“冷管线(Cold Pipe)”,它们具有完全独立的指令读取单元和执行单元。
其中,“热管线”主要负责执行动态指令,在架构方面较“冷管线”要复杂一些,设计思路大部分来自于Pentium4,主要包括了追踪缓存(Trace Cache)、热执行单元(Hot Execution)、追踪优化器(Trace Optimizer)、追踪选择过滤与构建逻辑(Trace Select Filter&Build)和追踪预测单元(Trace Prediction)等;“冷管线”专门负责执行乱序指令,其逻辑设计主要继承了Pentium M架构,主要包括指令缓存(Instruction Cache)、冷执行单元(Cold Execution)和分支预测单元(Branch Prediction)。
从“热管线”和“冷管线”的主要组成结构中我们可以发现,这两个管线的缓存单元有着明显的不同——在“热管线”中所使用的缓存来源于Pentium4的“追踪缓存(Trace Cache)”,这样设计带来的好处便是可以避免分支预测失败所带来的任务从零开始的现象;而“冷管线”中使用的缓存就是普通的指令缓存。由于热核需要处理平时多达80%的常用任务,所以强大的硬件设计是完全可以理解的;而冷核只需要处理那剩余的20%任务,所以硬件设计方面的简洁也是必要的。这样的设计既可以做到执行任务的高效性又能达到降低功耗的目的。
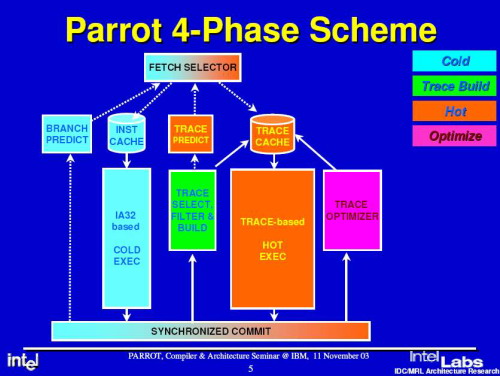
我们也可以将Parrot体系当作“双核心架构”,但这种双核心架构与现在的Pentium D、Athlon 64 X2有所不同。Parrot体系的“双核心架构”是指在一块处理器内部集成了热核和冷核两个非对等处理单元。当处理器开始运行指令的时候,位于整个逻辑前端的预取选择器(Fetch Selector)将会首先判断该指令是属于“热码”还是“冷码”(这一步在传统的x86体系中不存在),然后依次送入对应的执行管线进行处理——如果判断出指令为乱序指令,那么它将会被送到“冷管线”中被高效地处理;如果判断出指令为动态指令,那么它将会被送到硬件规格相对完善的“热管线”中被执行,处理完成以后将其所得的结果送往“同步合成单元(Synchronized Commit)”组合汇总。
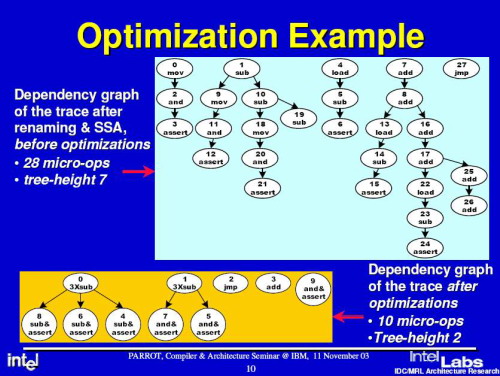
如果指令达到“同步合成单元”以后还存在动态指令,那么它将被送到“追踪优化器”进行优化,通过优化操作以后,其复杂程度将会大大降低、指令数量也会大大减少,这样一来,“热管线”执行效率就更高了。Intel官方资料显示,一条动态指令在未经过Parrot处理以前有7级树结构、涉及到28个微操作,而经过Parrot处理后,指令树深度减少到了2级、涉及到的微操作也只有10个。当指令被完全消化处理以后,再通过处理器前端总线传输给系统内存,从而完成整个处理过程。
65nm制造工艺对处理器的影响
按照Intel的规划,一种制造工艺的使用周期在2年左右。原本计划在2005年使用的65nm制造工艺由于一些不可预见的原因,被迫推迟到了2006年。这样一来,预计在2007年推出的Merom、Conroe和Woodcrest极有可能采用65nm制造工艺。65nm制造工艺到底能为下一代处理器带来什么样的好处呢?
制造工艺的进步主要体现在处理器内部导线长度进一步被缩短。由于晶体管之间都是由导线进行连接,提升制造工艺可以缩短导线的长度,增强产品的集成度。试想一下,上亿只晶体管之间的导线一起缩短,其情形是多么壮观!制造工艺的提升不仅让导线长度大幅减小,而且还会使晶体管门长度缩小,从而让处理器核心的面积减小得更加彻底。由于处理器集成度提高了,在采用相同数量晶体管的条件下,处理器核心面积将进一步缩小,这时同样大小的晶圆所能生产出的处理器会更多,从而可以实现降低生产成本的目的。
另一方面,由于目前处理器主要是由CMOS门电路所构成,而CMOS门电路的功耗可以由计算公式P=CfV2得出。缩短导线长度和门长度大小带来的好处便是使驱动电流减弱,电流与功耗两者之间存在着正比关系,从而降低工作电流就间接地让CMOS门电路的功耗得以降低。由于处理器核心集成了千万只甚至上亿只晶体管,就算是驱动电流下降一点,整体的效应也是相当可观的!还有,由于门长度的缩减会使晶体管的电容随之减小。就90nm制造工艺转换到65nm制造工艺而言,晶体管的电容C减小了20%。同样根据功耗公式可以看出,千万只甚至上亿只晶体管整体功耗下降程度相当可观。
在65nm制造工艺中,Intel使用了8层铜互连技术,比90nm制造工艺所采用的7层铜互连多了一层。从理论上看,处理器内部逻辑电路层数越多,在晶体管数目一定的条件下,它所占用的面积也就越小,从而也可以更好地控制生产成本。
结语
就目前所得到的关于Intel下一代处理器的资料来看,Parrot架构的引入可谓意义重大,它具备了攻破K8费心构建的高性能低功耗城墙的能力!从现在的情况来看,AMD并没有明确表示会开发出自己的下一代处理器产品。如果真是这样的话,那么我们对K8架构抵抗Intel下一代处理器的结果深表忧虑。就算未来AMD的处理器能全面支持DDRⅡ甚至DDRⅢ,但它们所拥有的性能也绝对无法赶超Merom、Conroe和Woodcrest!距离Intel下一代处理器正式发布尚有一年多的时间,在这一年多的时间中,AMD能否及时开发出与Intel相抗衡的产品?就让我们拭目以待吧,时间会告诉我们想知道的一切。