迟来的帝国反击战——ATi Radeon X1000系列技术特点分析
技术大讲堂
经过多次跳票之后,ATi终于在2005年10月5日给我们带来了代号为R520的Radeon X1800系列,及其中低端衍生产品X1600系列(代号RV530)和X1300系列(代号RV515)图形显示芯片。新的Radeon X1000系列到底有什么独特之处呢?它能胜过目前正在高端市场上独领风骚的G70吗?
R520技术特点分析
ATi为其新一代图形显示芯片采用了新的名称:Radeon X1000,其中核心代号为R520的显示核心是最高阶版本,取名为Radeon X1800,而核心为RV530的Radeon X1600系列和核心为RV515的Radeon X1300系列则分别面向中、低端显卡市场。

Radeon X1000由台积电(TSMC)代工,是全球最先采用90纳米制造工艺的图形芯片,在相同核心面积下能容纳更多的晶体管:R520内置了3.2亿个晶体管,是时下晶体管数目最多的显示核心(NVIDIA的G70拥有3.02亿个晶体管),是上代产品 R480的两倍。
R520图形显示芯片
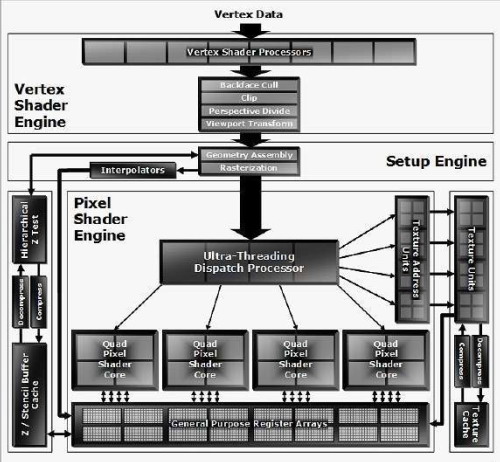
1.像素渲染流水线架构:Ultra-Threading 分派引擎
根据ATi官方提供的数据,R520只拥有16条像素渲染流水线及8个顶点着色引擎,和上代Radeon X850的R480核心相差不远,但两者在性能上的差异却不小。R520除了正式支持Shader Model 3.0(以下简称SM3.0)外,还拥有全新改良的3D引擎,ATi特地为R520的像素着色引擎起了一个全新的名称——“Ultra-Threaded Shader Architecture”。
从架构方面来看,R520的Pixel Shader(像素渲染)和R420(即Radeon X800系列)相差不大,所不同的是,增加了一个分支单元,并且计算精度从原来的FP24(24bit浮点)提升到了SM3.0所要求的FP32(32bit浮点)。
我们再来比较R520和G70的Pixel Shader,G70拥有两个能运行MADD(叠加乘积)指令的4D ALU,这两个ALU都能以4D、1D/3D或者2D/2D的方式完成指令,在运算能力上要强于R520。但G70存在一个不足之处,那就是ALU1还承担了纹理寻址计算任务(例如纹理坐标透视纠正的计算),在遇到纹理操作时,ALU1就不能执行像素着色器指令,而是执行纹理操作指令,只剩下ALU2执行像素着色器指令。
小知识:什么是ALU
ALU的全称为Arithmetic/Logic Unit(算术/逻辑单元),它负责处理数据的运算工作,包括算术运算(如加、减、乘、除等),逻辑运算(如AND、OR、NOT等)及关系运算(如比较大小),并将运算的结果存回记忆单元。对于图形芯片来说,ALU就是能够被编程使用进行图形计算的算术执行单元。
R520最值得我们关注的是引入了一个全新的“Ultra-Threading Dispatch Processor”(Ultra-Threading分派引擎)的概念,它也是有点类似于传统的SIMD超标量设计(其实NV40和G70中也采用了类似的设计)。这个引擎能够为一个像素着色处理器矩阵分配高达512个线程。这些像素着色处理器被按照4个一组的方式绑在一起,每个组被称为Quad Pixel Shader Cores(方阵像素着色器内核)。各个内核都是彼此相对独立的处理单元,能够处理一个2×2的像素块。
一旦Ultra-Threading分派引擎检测到某个方阵像素着色器内核处于闲置状态,就会立刻分派一个新的线程供其执行;如果闲置的原因是在等待其他像素着色单元的结果,它就会冻结其现有工作并空出其他ALU来执行其他指令。这样,方阵像素着色器内核在大多数时候都处于工作状态,充分利用了系统运算资源。据ATi介绍,这样的设计可以让X1800的Pixel Shader内核保持超过90%的利用率。
ATi的Ultra-Threading架构还能够提高Pixel Shader 3.0动态分支的性能。动态分支被认为是Pixel Shader 3.0的重要特性,可以让Pixel Shader根据计算出来的数值来运行不同的分支或者循环,从而显著地提高性能。例如在使用Shadow Map(阴影贴图)时,如果要对阴影进行边缘柔和取样,使用动态分支可以在遇到不需要取样的像素时跳过去,从而节省大量的Pixel Shader运算资源。
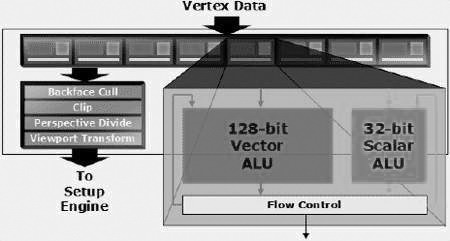
2. 顶点着色引擎:每秒可完成100亿条顶点着色指令
从架构上看,R520的Vertex Shader和R420的Vertex Shader非常类似,采用的是“128bit矢量ALU+32bit标量ALU”搭配的方式。值得一提的是,ATi终于在新一代图形芯片中加入了对Vertex Shader 3.0的支持,并可执行1个128bit 浮点运算或是4个32bit浮点运算的组合,这个特征可以在显示芯片上仿效CPU的运算模式。因此,R520的顶点处理器在每个时钟周期内可执行2条Vertex Shader指令,8个Vertex Shader每个周期一共能完成两个顶点的转换操作。这意味着R520每秒可以完成100亿条Vertex Shader指令。理论上,Radeon X1800 XT在顶点着色引擎运算效率方面要高于GeForce 7800 GTX。
和R420不同的是,新的R520由于引入了SM3.0,Vertex Shader也因此支持3.0,包括像分支、循环、子程序等动态流控制指令都获得了支持,每条Vertex Shader程序长度可以达到1024条指令。不过,和GeForce 6xxx和GeForce 7xxx不同的是,R520的顶点着色引擎中并没有Vertex Texture Fetch(顶点纹理拾取)单元。因此,ATi采取了一个另类的方案:Render to Vertex Buffer(渲染到顶点缓存)来实现类似功能。
SM3.0的Pixel Shader输出的4个FP32矢量的128bit浮点格式数据可以存放到顶点缓存,Render to Vertex Buffer的原理就是将这些数据直接作为顶点数据传输给顶点着色器,以此来实现Vertex Texture Fetch的类似功效。不过和真正的Vertex Texture Fetch相比,Render to Vertex Buffer可能略显缺乏灵活性及效率,毕竟Render to Vertex Buffer 存在一个转换过程,如果置换贴图的物理数据要发生改变的话,整个渲染过程也要随之配合变动。而只要拥有Vertex Texture Fetch 功能,Vertex Texture Fetch中的纹理在Vertex Shader中就可以很快地进行动态取样,顶点数据可以实现动态变更,更容易加入几何数据。
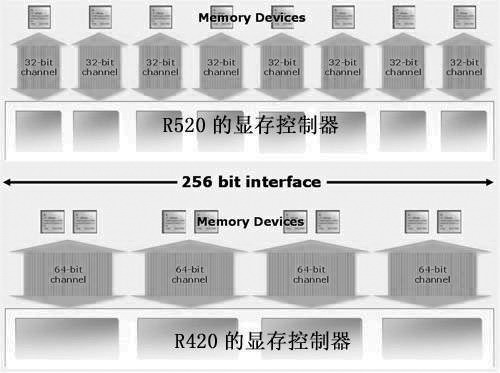
3.显存架构:环路总线技术
自R300(即Radeon 9700系列)开始,ATi在图形芯片中都采用了256bit显存总线设计,由4个64bit的DDR显存控制器负责数据传输。不过,这样的显存架构设计存在一个缺点:如果芯片需求的数据块小于显存控制器“胃口”(如32bit数据块),此时控制器的利用率只有50%,这样在遇到只需要传输小块数据时,就会大量浪费显存带宽。因此,如何更高效地利用显存成为了厂商们在设计显存控制器时所面临的一个难题。
针对传统显存控制器的缺点,ATi在R520中采用了32bit显存控制器设计,即在Radeon X1800中,有8个32bit内存控制器。当有8个32bit的数据要传送时,理论上它只要一个时钟周期就能完成,但X850的64bit并不能同时传送两个32bit数据,它需要比R520多一倍的时间才能完成。因此,R520把通道变成8个32bit,使显存子系统在一些细小的数据存取方面更有效率。
虽然R520对外的显存位宽仍然保持256bit的标准,但内部却采用了512bit设计,这主要是因为R520的显存控制器采用了环路拓扑结构:即R520的显存总线由两组双向256bit环路总线组成(Radeon X1600的环路拓扑架构由两组双向128bit环路总线组成,而Radeon X1300系列不支持环路总线技术,但ATi表示会另辟蹊径来改进Radeon X1300显存子系统的性能)。
环路总线围绕在内核周围,这样可以简化线路设计及使连接处于最优化状态。这意味着任何时候内核各部件都能处于最短的连接线路状态,在显存进行数据写入操作时,能有效减少延迟。R520的显存架构环路总线中的连接点被称为“Ring Stop”,整个架构中共有4个这样的连接点:每个Ring Stop拥有两条32bit存取通道,每个Ring Stop都依照显存控制器发出的指令,根据显存的数据请求将数据发送到各个存取通道中,这样可以充分利用显存带宽资源。
除了采用环路总线设计外,ATi在X1000系列中还引入了一种“联合缓存存取工作模式”来提升显存系统的性能。此前,图形芯片中采用的缓存都是直接映像,即每个缓存的入口都映射至一个专门的图形显存区块。虽然这可以让缓存的执行简单化,不过也带来了一个问题:当显存需要同时交换两个数据,而这两个数据刚好位于被缓存映射的同一显存区块内时,这两块数据就会出现抢占缓存空间的情况,从而产生延迟,降低缓存的命中率。而在联合缓存架构中,缓存不再只是映射到特定一个或者某几个的显存地址,而是任意空闲的显存,这就大大提高了工作效率。
除了性能上的改善,ATi并没有忽略提升芯片的画面显示品质,比如,R520除了支持Shader Model 3.0外,还加入了HDR(High-Dynamic Range,高动态范围)渲染功能,以及全新的Adaptive Anti-Aliasing(自适应抗锯齿)与Area Anisotropic Filtering(全方位各向异性过滤),这使得R520将比上代产品提供更优秀的3D显示效果。在2D方面为了和NVIDIA的PureVideo看齐,ATi首次在芯片中加入AVIVO视频解决方案,成为首款硬件支持H.264解码的图形核心。
结语
ATi终于推出了新一代显示核心,而且在架构上也有很大的改良,加入AVIVO功能令它拥有多媒体硬件编码能力。不过,很多人还是担心R520的良率问题,早前曾传出ATi 新一代90纳米制造工艺的良率较低,R520一再延期也说明了问题的严重性。因此Radeon X1800XT能否大量出货确实令人疑虑。据说ATi已经与UMC公司商定了关于X1000系列显示核心代工的相关事宜,这意味着ATi将加快新一代产品的市场推广速度,这也有利于降低产品的生产成本。因此,我们更希望看到新产品能在11月份如期出货,毕竟市场变化瞬息万变,机会稍纵即逝!相信ATi比我们更清楚这一点。