CPU背后的秘密——细说缓存提速
技术大讲堂
一、缓存作用篇
近日一位爱动脑的朋友问我一个问题,他听老鸟说,在计算机内部,高速设备与低速设备之间设置缓存可以有效提升系统整体性能,原因在于高速缓存内部通常存储了一些常用的数据指令,当系统重复调用这些数据指令时就可以快速从中获取,进而达到提速的效果。但计算机里还存在一些按顺序存储的设备,在这些设备中设置缓存是否也能起到同样的提速作用?
对此他持有否定的观点,而且他还画了一个图来讲解(图1)。他用水来比喻指令,不同设备之间传输速度的差异由连接管道的粗细区分。上半图中,水要从A流至C只能通过一个狭窄的管道,这时如果我们在A-C之间设置一个水库B(缓存),水库与C设备连接的管道相对要粗不少。依据“短板原理”,单位时间内从A流出的水的总量是一定的,而且对于整个系统来说水的流量只取决于最窄的那条管道的宽度,所以他认为在顺序存储的设备中设置缓存没有意义。那事实到底如何呢?下面我们就来分析看看。
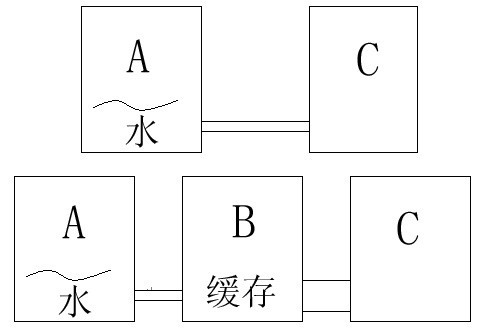
这位朋友的说法乍听起来确有几分道理,但他的说法成立的前提条件是水源源不断地从A设备流向C设备,这种情况下在中间环节设置缓存确实没有实际意义。但现实中的计算机工作原理与这个例子却有着本质的区别。首先我们知道计算机是按照一定“节拍”工作的,因此某种意义上说它的工作是不连续的,而且指令到达CPU后还需要经过编译执行等步骤,这些都需要耗费一定的时间。回到图1的例子,我们可以假设在C设备入口处设置了一个开关,开关按照一定的时间间隔开启关闭,如果我们能利用开关关闭的时间把水及时送入B缓存里,这样开关下次开启时水就可以通过宽通道快速流入C设备了,因此在顺序存储的设备中架设缓存同样也能达到提速的效果!
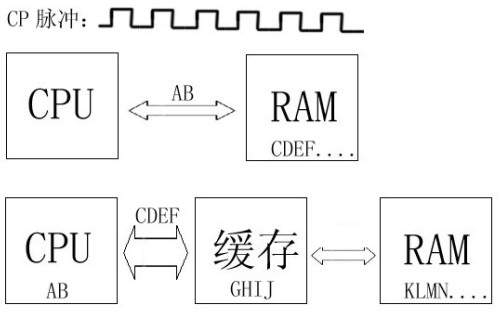
为了帮助大家进一步理解,我们举例说明,此例我们仅让CPU依顺序从RAM中读取一串字母,其他更复杂的情况我们将在下文的算法篇进行阐述。举例前还要说明的是,为了方便大家理解,此例我们忽略了缓存延迟、查找时间等其它一切外界因素,仅考虑最简单的情况。
如图2所示,CPU按照一定的CP脉冲从RAM中顺序读取ABCDEFGHIJKLMNOPQR 18个字母,图2上半部为CPU与RAM直接相连的情况,限于RAM的工作速度,每个周期只能传送两个字母到CPU,这样传送18个字母共需要9个周期。如果在CPU与RAM之间架设一个高速缓存,这样一个周期内CPU就能从缓存里一次性读取4个字母。我们模拟一下此时的数据通路,第一个周期CPU在缓存里查找字母AB,没有发现所需字母于是继续在RAM中查找到字母AB并将其送入缓存,第二个周期字母AB从缓存被顺利送入CPU,同时利用CPU执行指令的空闲时间,缓存从RAM中连续读入与AB相临的4个字母,这样以后每当一个周期来临时CPU就可以一次性从缓存里连续读取4个字母了,5个周期后18个字母被全部读入,相对上面那种直连的情况节省了4个周期的时间。
二、算法篇
也许有的朋友看到这觉得缓存提速不过如此嘛,本文到此似乎就该结束了。但大家别忘了,上述举例的前提是CPU读取数据指令的方式是按顺序进行的,而且这种次序已经事先人为排列好了。而现实中由于指令执行的不确定性和大量跳转指令的存在,面临要解决的一个重要难题就是后继指令的侦测预取。同时由于成本限制导致缓存的容量有限,因此决定哪部分数据可以保存在缓存里,哪部分需要被替换掉也是一个棘手的问题,这就涉及到了缓存的替换策略,因此一切比想象的要复杂得多。如果说缓存是系统提速的承载物质实体,那么下文将要介绍的算法则是系统提速的灵魂!
说到指令的预取算法有的朋友可能会顿感头晕,上例中我们利用CPU空闲时间从RAM中顺序读取相临的4个字母到缓存,其实这就是一种最简单的预取算法,尽管在现实中这种算法效率很低,不过实现起来却很容易。
针对上文所谈及的缓存替换策略,这里将介绍两个比较简单的替换算法,旨在通过两种算法效率的比较让大家认识到一个优良的算法对于系统提速的重要性。
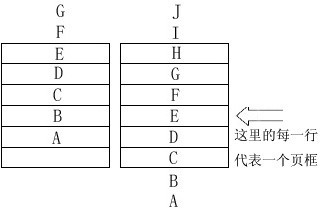
1.FIFO(First In First Out):先进先出算法,我们可以把它理解为有序数据组成队列后定向地流入流出,图3所示的指令队列按顺序从缓存区的上口流入,下口流出。还有后文还将要提及的“页框”概念,大家参看图3说明就能了解。
2.LRU(Least Recently Used):近期最少使用算法,简单说来LRU算法是将近期内长久未被访问的数据行换出,我们可以在每行设置一个计数器,此行每被命中一次,计数器就自动清零,其他行则增1,当需要对行数据进行替换时可以比较各行的计数器,将数值最大的那行数据替换出去,这种算法保护了刚刚拷贝进来的数据,提升了系统的命中率。
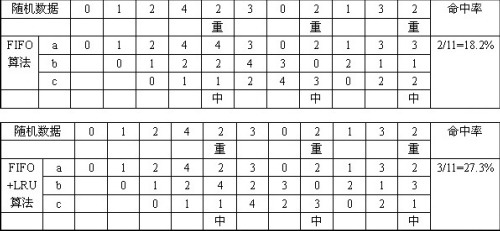
大家对以上两个算法可能还不太明白,我们再举例说明,这里的举例有别于文章开头的那种简单的顺序读取,而是一种更常见的情况。假设主存只有三个页框a、b、c,我们随机给出11个数据0、1、2、4、2、3、0、2、1、3、2并将其组成FIFO队列,然后通过CPU的读取分别比较FIFO算法与FIFO+LRU算法的命中率。具体实现步骤如下表。
为了帮助大家理解这两个表格,我们简单解释一下,表格的第一行列出了随机给出的11个数据,第二行带有“重”字的说明此数据前面曾出现过,在此是重复出现。数据每个周期替换一个次,从a口入c口出。先看表格1,由于采用了FIFO算法,最先进入页框的数据也会被最先替换出来。当表格1中出现第一个重时,也就是数据2重复,下个替换周期到达时此列页框内的数据就暂停替换一次,保持现态,依此类推。最后经过计算,FIFO算法的命中率为18.2%。我们再看表格2,表格2的算法对1进行了改良。这次遇到第一个重复数据时不仅暂停替换一次,还把重复出现的那个数据调换到队列的末尾,这样就延长了此数据的生命周期。其余部分表格2与表格1一样,通过计算,改良后的FIFO+LRU算法命中率为27.3%,比前者提升了9.1%,由此大家可以看出,同样的缓存,不同的算法,带来的效率差距却是巨大的。
我们再联系一下实际,放眼如今的CPU市场,赛扬D性能之所以远好于老赛扬,二级缓存的加大功不可没。但当Intel把CPU内部的二级缓存从512KB提升到1024KB甚至更高时,带来的性能提升却有限,前者限制系统性能的主要因素是缓存容量,而后者则是由分支预测算法的改进有限造成的此时限制系统性能的主要因素就变成了算法。但需要大家注意的是,CPU性能的提升由多方面因素共同决定,这里提及的缓存仅是其中之一。至此我们能够得出结论,缓存的提速应从容量和算法两个方面共同努力。还有朋友问了,既然算法对缓存提速如此重要,为什么厂家们都更愿意在容量上做文章呢?笔者分析原因大概如下:
1.从市场营销学的角度来说,缓存容量的提升是直观可见的,大容量的贵小容量的便宜,普通消费者很容易比较和接受。而算法则是一个十分抽象的东西,而且高级一些的算法通常需要外围硬件的支持,硬件成本的提升并不少,所以采用算法优劣来划分产品市场将很难引起消费者的共鸣,因此Intel才采用二级缓存的大小作为划分产品市场的策略之一。
2.一个成熟高效算法的开发过程并不像想象的那么简单,期间同样需要投入大量的人力和财力,而且就算如此也不一定能取得预期的效果,厂商还要为此承担巨大的商业风险,根据趋利避害的原理,他们宁愿选择简单奏效的增容法。
以上两则观点仅是笔者个人的愚拙之见,大家对此也可以持有其他不同的看法。
三、讨论思考篇
本章节的内容没有固定的答案,笔者这里抛砖引玉,提出一些想法,并进行简单的解析,希望可以引发大家的思考。
1.增加缓存容量和级数面临的主要困难有哪些?
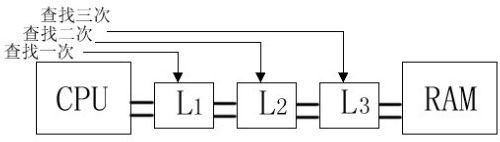
增加缓存容量所面临的困难,包括成本、发热量以及制造工艺等等,而增加缓存级数则要面临更多的困难,上文的举例忽略了很多外界因素,其一就有CPU在缓存里查找所需数据而耽搁的时间,尤其在多级缓存中,经常需要进行多级查找(图4),此时查找浪费的时间就更不能简单忽略了,还有大家知道缓存的内容本质就是低速设备中一部分内容的镜像,在多级缓存中,一级缓存是二级缓存的镜像,同理二级缓存是三级缓存的镜像,因此如何解决好多级缓存之间内容的同步与替换更是一个浩大的系统工程。
2.在成本相同的情况下,是搭建多级缓存对系统性能提升大还是尽量扩大单级缓存的容量对系统性能提升大?
这是一个较复杂的问题,我们在此还是排除延迟、查找时间和工艺等外界因素,仅针对具体一方面进行理论上的探讨。我们针对以上两种情况搭建两个模型,如图5,同时还约定这两个模型采用同样的预取算法,缓存速度B1>B2=B3。上半部分是一个多级缓存的模型,下半部分则是单级的,此外了我们讨论的前提是在相同的成本下。一般来说缓存的速度与价格成正比,所以依据这个原则,速度越快的缓存容量应越小。在图5的上半部分这种情况中,大部分时间里如果C设备都可以在B1中找到想要的数据,而缓存B1的速度又非常快,所以在这种情况下显然是多级缓存的效率更高,但如果大部分时间里B1中没有C设备所需的数据,C设备就须访问B2继续查找,相对图5下半部分的单级大容量缓存来说,B2的容量远小于B3,因此B2所能装载的内容也就较少,因此找到相应指令的概率也就小很多,这种情况下单级缓存就更有优势。
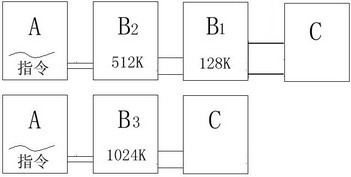
通过上面的比较,我们发现了平衡级数与容量关键性的一个因素,那就是预取算法的命中率,在命中率较高的系统里,多级缓存可以对预取到的数据在小容量高速度的缓存中快速调用,显著提升系统性能,而在算法命中率较低的设备里,单级大容量的缓存则凭借其“有容乃大”的优势更胜一筹。再从制造工艺的角度阐述,单级大容量的缓存实现起来相对要容易一些,而多级缓存无论从布线复杂度上还是缩短控制信号延迟方面实现起来都要复杂得多,因此多级缓存目前仅在预取算法效率较高且工艺较成熟的CPU内部才得以一试身手,而其他大部分设备里单级缓存则牢牢占据了霸主的地位。通过上文的讲解我们还得出多级缓存与单级缓存的本质区别,那就是多级缓存采用了阶梯式的分层结构,因此多级缓存中各级缓存的速度是有差别的,如果都一样的话就起不到应有的提速作用了。
四、缓存的其他应用
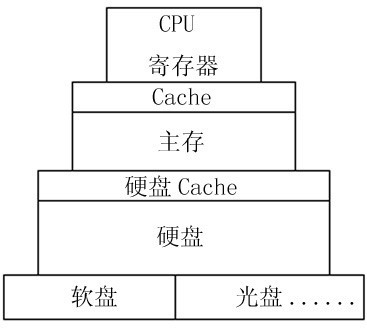
计算机里缓存无处不在,外部设备的数据与CPU之间的双向交换需要经过层层缓存(图6),计算机内部的缓存除了起到提速的作用,还有几种其他重要的应用:
1.稳定数据源与暂存数据:现在是DVD刻录机盛行的时代,DVD刻录机里普遍搭配了大容量的缓存,这里的缓存主要是起到了类似于水库的作用,当下游缺水时及时开闸补给,避免“欠载”情况的发生;而当下游水量过剩时就关闸限水,总之就是要保证数据持续稳定的输出,这也是刻录成功的重要保证。再有就是数据暂存,系统内部有很多的设备,而系统的资源却又是有限的,当几个设备同时争夺系统资源时就会交由仲裁电路对其进行判断,优先级低的设备也就只能等待了,比如我们在键盘输入一排按键,但这时系统资源正被其他设备使用,这时输入的信号就会暂存在键盘的缓冲区里,等待系统资源的释放,避免了数据的丢失。
2.同步信号:虽然目前数据的传输正朝着串行的方向发展,但计算机内部依然有很多总线采用了并行的传输方式,在相同频率下并行传输依旧占有很大的优势,数据并行传输前在发送端需要被打散,以便送到各条分线路上;而在接收端接收到数据后需要对其进行重组。在数据传输的过程中,由于电磁干扰和布线工艺等因素会导致它们很难同时到达接收端,如果马上就对其进行重组势必导致次序的紊乱以及数据的丢失,这时就需要在接收端设置缓存等待所有数据的到达,用以同步信号,避免上述情况的发生(图7)。

至此文章告一段落,希望此篇文章可以为大家进一步了解缓存提供一些帮助!