巧用Office 2003识别图片中的文字
办公族
如果大家经常在网上下载各类文章,要是遇到有的站点出于版权考虑,把一些书籍直接用扫描仪扫进去,然后插入到网页中去,这种情况下图片里的文字怎么复制下来呢?其实我们可以利用Office 2003工具中提供的Document Imaging程序,进行“光学”识别,来解决这个问题。
1.打开浏览器,打开一个包含文字的页面文件,然后在键盘上按“Print Screen”键进行抓屏,将网页作为一幅图片抓到剪贴板中去。
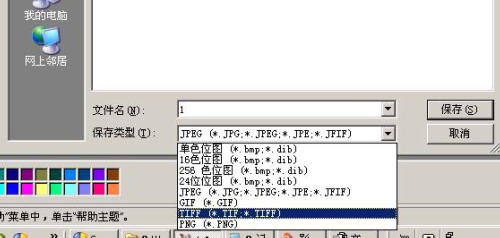
2.打开Windows自带的画图程序,依次选择菜单“编辑→粘贴”,将刚才复制到剪贴板中的页面图片文件粘贴到画图中去,然后选择“文件→保存”进行存盘。这里有个关键点要注意,就是Document Imaging只能识别TIF格式的图片,所以存盘的时候一定要注意要把文件格式改为TIF格式(如图1)。
3.依次选择“开始→程序→Microsoft office→Microsoft Office工具→Microsoft Office Document Imaging”,Document Imaging是一个专门用来扫描文档的工具。在 Document Imaging中打开刚才画图中保存下来的tif格式的文件。
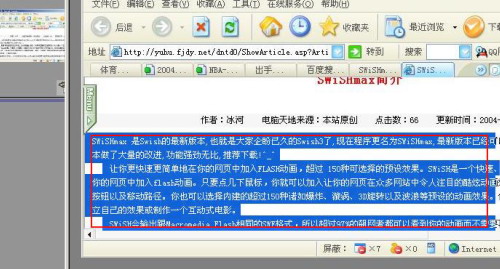
4.由于这里我们不需要将图片中所有文字元素全部识别,所以,我们可以选择工具栏中的“选择”工具,来选定一定范围内的文字,这样就实现了有针对性的识别(如图2)。
5.依次选择“工具→使用OCR识别文本”,就会出现进程条,表示当前正在识别。
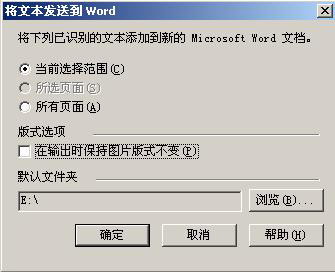
6.依次选择“工具→将文本发送到Word”,就会弹出对话框(图3)。由于我们只想识别我们选定的文字,所以在范围项选择“当前选择范围”;由于我们不需要对图片作处理,所以下面“输出时候保持图片版式不变”就不需要选择了。另外单击“浏览”按钮,选择马上输出的Word文档保存的位置,确定以后就会自动调用Word 2003,并且将识别后的结果显示出来(如图4)。
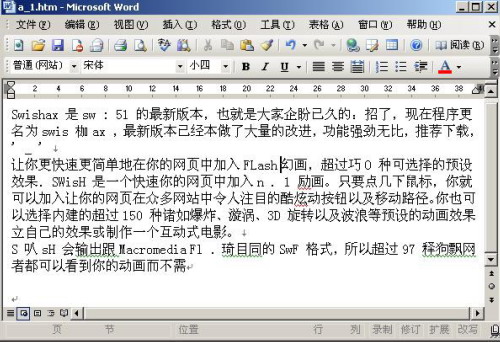
刚才还是一幅图片,转眼工夫就成了一篇文章,是不是很神奇?仔细检查一下,发现还是有几个错别字和错误的符号。光学扫描仪的OCR功能也不能达到100%的准确,我仔细算了一下,扫描的准确率可达到90%以上,还是有很大的实用价值的。我认为要提高识别准确率应该在提高图片质量上做文章,希望感兴趣的读者能在这方面多研究研究,更进一步用好Document Imaging的这一光学识别功能。