抛弃PCI 迎接PCI Express时代(下)
技术大讲堂
PCI-E的向后兼容性
可能各位也听说过PCI-E的向后兼容性,也就是说你的操作系统和应用软件能在不改变任何条件的情况下在一个有PCI-E设备的系统上正常运行。为什么PCI-E具有这样优异的兼容性呢?
PCI和PCI Express都采用了类似于网络OSI模型的结构。简单地说一下它们的模型,这样能让你更好地理解PCI Express具有如此良好的向后兼容性的原因。
OSI模型指的是将一个系统分成若干层次,处在高层次的系统仅利用较低层次提供的接口和功能,不须了解低层次实现该功能所采用的算法和协议;较低层次也仅使用从高层次系统传输来的参数,这就是层次间的无关性。因为有了这种无关性,层次间的每个模块可以用一个新的模块取代,只要新的模块与旧的模块具有相同的功能和接口,即使它们使用的算法和协议都不一样。
OSI模型的好处在于:如果其中的某一层需要升级,其上下层并不需要做改动。设计者只需在对某一层升级时维持该层与其上下层的接口不变即可,不需要重新设计整个系统。
PCI Express 体系结构共分为四层,从下到上分别为:物理层(Physical Layer)、数据链路层(Link Layer)、处理层(Transaction Layer)和软件层(Software Layer)。
由于PCI Express的设计者并没有改变PCI软件层接口,而仅仅改变了其物理接口,所以原来为PCI设计的软件仍然可以在PCI Express系统上运行而不须改动。虽然处于PCI-E的系统,但对现在的操作系统或者某特定软件来说,它们认为读写的就是PCI总线而非PCI-E总线。也就是说,读写PCI-E上的设备对应用软件来说就像是在读写PCI设备一样,没有任何区别。
这样,我们更新PCI到PCI-E就无须更新整个系统,只要改变需要改变的部分即可(物理连接以及分组交换协议)。由此我们也能看到PCI在设计时的前瞻性。
PCI-E的传输通道(Link & Lane)
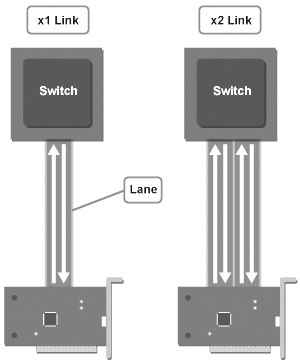
PCI-E设计者在设计的时候,面临的首要问题是PIN数的控制。在上期PCI部分,我们已经分析了PCI总线由于采用并行总线技术而导致成本、干扰以及工作频率的极限问题。也因为并行总线的种种不利因素,PCI-E的开发者选择了串行总线。
在PCI-E规范中, PCI-E交换机和PCI-E设备之间建立的连接叫Link,每一个Link则是由一个或多个Lanes构成,而每一个Lane在一个时钟内能双向传送一个byte的数据。全双工模式在一个Lane内是可以实现的,因为在每一个Lane里有两个信号:接收和发送。
PCI-E采用的是分组交换技术。在只有一个Lane的Link中,数据被发送端分割成一个个小片断(分组),并一个个依次发送到接收端。接收端设备把一个个数据片断接收后重新组合成原来的数据(重组),以完成数据的传输。而在有多个Lane的Link中,被分组的数据片断可以从发送端通过多个Lane快速到达接收端,这跟我们常用的“多线程”下载类似。同时,这也是分组交换带宽利用率的体现。数据的分组和重组必须足够快让数据能完整地被传送到上层,这也意味着在每个Link的两端必须有足够快的处理器来处理分组和重组任务。
让人欣喜的是,PCI-E支持Lane之间的合并。也就是说,我们可以用两个Lane来建立交换机和PCI-E设备的Link,这样在一个时钟内,就可以向两个同方向传送2个byte的数据。也就是说数据传输速度增加了一倍。而你更可以在一个Link内加入更多的Lane来加快PCI-E的速度,比如你可以加入4个、8个等。现在应用的PCI-E×16就是用16个Lane来实现高速数据传输的。
一个只含有一个Lane的Link我们称为×1 Link,含有2个Lane的Link我们称为×2 Link,依次类推,一直到×4、×8、×12和×16的Link。
PCI-E的带宽相对PCI来说是有很大提升的,一个Lane的数据传输率能达到2.5Gbps/每方向,如果是×2 Link的话宽度更可达5Gbps/每方向。大家都知道PCI-E×16就是有着16个Lane构成一个Link。其传输速度可达2.5Gbps×16=40Gbps =5GByte/s/每方向。当然,在实际的传输中,不可避免地需要加入地址信息、控制信息,5GB/s的传送速度不过是其理论值。
Lane 之困惑
也许我们在一些产品评测中看到,市场上并没有推出真正支持双PCI-E ×16的主板。所谓的双PCI-E主板在插双显卡的时候,每块显卡仅仅是PCI-E ×8速度。只有插单显卡的时候才跑在×16的速度。这到底是怎么回事呢?下面的图可以帮你清楚了解这个问题。
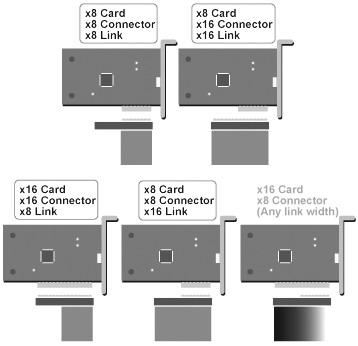
按上图所示,分成5种情况:
1.显卡采用的是×8的Link,×8的接口,而主板也采用×8的Link,×8的插槽。这样显卡就跑在×8的速度上。
2.显卡采用的是×8的Link,×8的接口,而主板采用×16的Link,×16的插槽。那么显卡也跑在×8的速度上。此时主板上多余的Lane就会被闲置。
3.显卡采用的是×16的Link,×16的接口,而主板也采用×8的Link,×16的插槽。这样显卡也跑在×8的速度上。此时显卡上多余的Lane被闲置。
4.显卡采用的是×8的Link,x8的接口,而主板也采用×16的Link,×8的插槽。这样显卡也跑在×8的速度上。此时主板上多余的Lane被闲置。
5.这种情况是不能工作的。即显卡采用×16的Link,×16的接口,而主板采用×16或者×8的Link,×8的接口。
这种Link宽度的协商对兼容性和整个系统的整合是非常有益的,但对用户来说可能是比较头疼的事。用户必须搞明白他们的主板到底是支持×16还是用了×8的Link和×16的插槽?
PCI-E与PCI之间的桥接
或许我们已经听说了PCI-E到PCI的桥接,这也是PCI向PCI-E转型必然出现的事物。其实AGP也属于PCI范畴,只是AGP是高级的PCI而已。
PCI-E到PCI的桥接芯片把分组的串行包转换成传统的PCI信号,以方便传统的PCI设备在新型的PCI-E主板上使用。而Intel为了兼容PCI设备,其最新的ICH6南桥还是保留了PCI插槽。
实际上,桥接的方式被大量运用到显卡上,比如NVIDIA就曾推出过桥接方式(HSI)的PCI-E显卡,显卡上有一个芯片用来做AGP到PCI-E的转换。所以这样的显卡称之为“使用PCI-E接口的AGP显卡”更合适。

随着具有PCI Express ×16接口的主板被越来越多的人所接受,PCI-E显卡取代AGP显卡将是不可逆转的发展趋势。
PCI Express,它已代表更多
我们曾说过,理想的总线是用一种高效的总线连接所有设备。在PCI-E上,我们看到了希望。在PCI力不从心的今天,PCI-E犹如初生牛犊,正在实现它一统计算机外围设备总线的梦想。
纵然PCI的架构在今天看来已经廉颇老已,但我们也不会忘记它曾在PC系统中的地位,以及它长达10年的辉煌历史,我们更不会忘记PCI-X是如何努力想让PCI常青,我们决不会忘记PCI的设计者使用OSI模型的睿智,尽管PCI将不可避免地完成它历史的使命。
PCI-E的出现,让我们联想到,也许在未来的计算机系统中,HUB-LINK,DDR,FSB,IDE等等都将会被一个更高速、通用性更强的总线所替代,这样的系统或许就真的是完美系统了。