2005年PC核心系统新技术速查
IT技术回顾
对于PC来说,主板、CPU、显示卡和内存构成了无可争议的基本子系统。在2005年,有众多的新技术应用在这些部件上,这也使PC的整体性能提升到了一个新的阶段。
一、2005年主板新技术
主板是PC各部件运行的纽带和桥梁。主板的核心是芯片组(Chipsets),它控制着主板上所有部件的运行,也决定了主板所能达到的性能水准和档次。
众所周知,大多数主板芯片组都采用了双芯片设置,即一块芯片作为北桥芯片,另一块为南桥芯片。北桥芯片负责CPU、内存和显卡的工作,而南桥芯片掌握着IDE、Audio和USB等设备的运行。习惯上以北桥芯片代指整个芯片组,如我们熟悉的Intel 955X芯片组,实际上就是北桥芯片为82955X和南桥芯片为i82801GR ICH7R的两块芯片组合而成。
1.全面支持1066MHz FSB
为了提供对Pentium D和Pentium Extreme Edition等高端处理器的支持,Intel i925X和nForce4 SLI Intel Edition级别以上的芯片组提供了对1066MHz前端总线(Front Side Bus,FSB)的支持,同时这些芯片组也向下兼容800MHz和533MHz两种FSB,并可以支持LGA 775接口的全系列Intel处理器。
2.内存加速技术
我们知道,影响内存性能的通常有两个因素:内存带宽和内存延时。
内存带宽就好比是一个管道的流量,越高的流量意味着越多的数据。内存延时就好比是这个管道的长度,越短的距离才能保证数据在第一时间流到需要它的地方。这两点同时影响着系统的性能,而且它们影响系统性能的方式并不相同:内存带宽,是由内存的位宽和内存的频率决定的,就好像是一条马路的宽度和车流的速度,只有马路越宽,车速越高才能最大限度地提高性能。内存延时,就好像是马路上红灯的数量,红灯越多,车辆就不得不停车起步很多次,耽误了很多的时间,同样对性能会产生很大的影响。
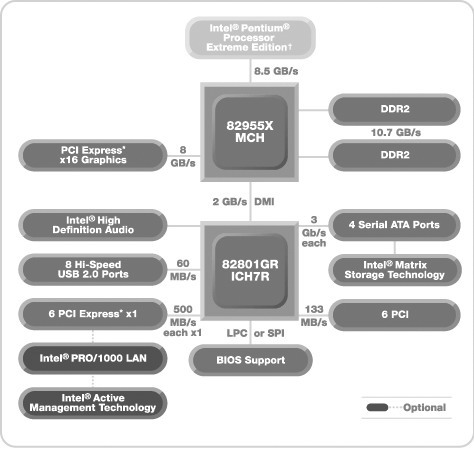
为了解决这个问题,在i955X芯片组中,Intel采取了新的内存加速技术,官方称之为“Intel Memory Pipeline Technology”,简称Intel MPT。它的主要应用原理是,通过加速处理器和系统内存的传输速度,以获得更高的内存使用效率。该架构还支持同步、异步的数据传输,使用独立的内部管线和仲裁机制。为了支持更高速内存,增加显示卡的需求和I/O带宽,i955X芯片组使用新的MCH(Memory Controller Hub,内存控制中枢),也就是传统意义上的北桥,负责内存和显示卡的数据交换。新MCH使用了更宽的内部数据总线设计,能够支持双通道DDR2 667内存(最高10.7GB/s的峰值带宽)。
此外,Intel还配备了Flex Memory技术,它可以提高双通道内存的兼容性。在i865/875主板中,双通道模式只能在内存成对模式下运行,但在i915/925/955系列芯片组中,即使同时使用三条内存也可以运行在双通道模式下:在同时使用三条内存模块的情况下,用户只要将两条内存安装在第一组双通道插槽,而另一条内存安装在第二组双通道插槽的第一个DIMM上,就可以让系统运行在双通道模式下。此外,该技术还能让不同品牌、不同容量的内存工作在双通道状态,兼容性提高了不少。
在nForce4 SLI Intel Edition芯片组中,使用了多种内存新技术来提升内存传输效率,主要包括双通道、提高总线利用率、DASP 3.0等特色技术。对于内存带宽,nVIDIA针对nForce4 SLI Intel Edition进行了两个方面的技术改造:首先在位宽方面采用了双通道的内存控制器,支持双通道的DDR2内存;其次,支持高速内存,提供了对DDR2 667内存的支持,并且采用对每个内存插槽分配独立的地址总线的方法来提高效率。
对于内存延时,nVIDIA着手于三个方面:首先,采用1T+4的突发长度,降低了延时;其次,采用了DASP 3.0猜测预取技术,提高了数据访问的准确性;最后,采用QuickSync快速同步技术,解决超频后引起的时序增加问题。
3.PCI Express×16以及PCI Express×1插槽成为主流
PCI总线拥有133MB/s的带宽,但随着技术的发展,越来越多的设备需要更大的带宽,例如千兆网卡等。PCI已经不能再满足传输上日益增长的数据量的需求。整个PC业界迫切需要一个统一标准取代PCI的总线技术,PCI Express就是这样一个角色。目前,基于PCI Express技术的主板已经全面取代AGP总线,成为主流。
与传统PCI以及更早期的计算机总线的共享并行架构相比,PCI Express采用设备间的点对点串行连接(Serial Interface)。它允许每个设备都有自己的专用连接,不需要向整个总线请求带宽,同时利用串行的连接特点就能轻松将数据传输速度提到一个很高的频率,也就能轻松提供目前PCI总线所不能达到的高带宽。

单个基本的PCI Express连接是一种双单工连接。相对于传统PCI总线在单一时间周期内只能实现单向传输,PCI Express的双单工连接能提供更高的传输速率和质量,它们之间的差异跟半双工和全双工类似。同时PCI Express串行连接使用了内嵌时钟技术(8b/10b模式),时钟信息直接写入数据流中。
一个PCI Express连接可以被配置成×1、×2、×4、×8、×12、×16和×32的数据带宽。×1的通道能实现单向312.5MB/s(2.5GB/s)的传输速率,同理×32通道连接就能提供10GB/s的速率。
PCI Express的接口根据总线位宽不同而有所差异,包括×1、×4、×8以及×16(×2模式用于内部接口而非插槽模式)等几种形式。较短的PCI Express卡可以插入较长的PCI Express插槽中使用,也就是说低位宽的设备能插入高位宽的插槽中使用。
4.增强的RAID存储技术
为了支持多硬盘的模式,并提高多硬盘下系统的安全性,Intel的ICH6系列南桥就开始支持Matrix RAID(矩阵RAID)存储技术,在ICH7系列南桥中,该技术依然被采用。
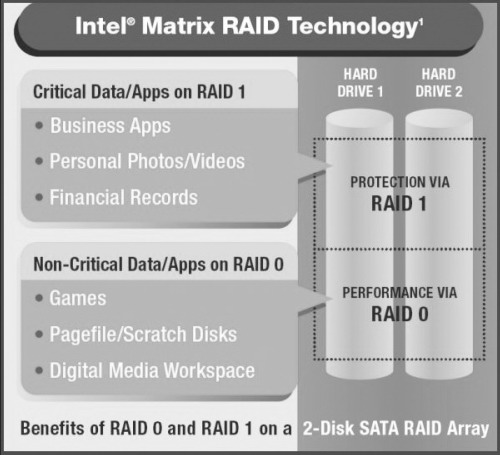
过去,PATA RAID控制芯片所能提供的RAID模式,仅限于RAID 0、RAID 1或RAID 0+1三种。其中,RIAD 0将原本需要由一个硬盘完成的工作交由两个磁盘来分工完成,理论上,速度可以提高一倍;RAID 1是将原本需要一个硬盘来保存的数据备份一份到另一个磁盘上,提高数据安全性。
如果要兼顾效能及安全性,就要采用RAID 0+1,但这需要4块硬盘,会浪费一半的硬盘空间,而且还需要配备高价的RAID控制器,对于那些既想要性能又想要安全性的用户,4块硬盘的花费再加上高价的RAID控制器不是每个用户可以接受的。这是目前众多用户在家用PC或者工作站系统上构建RIAD所面临的困境,也是RAID存储方案一直无法推广的原因所在。
如果利用Matrix RAID技术,用户只需要使用两个硬盘就可以同时创建RAID1和RAID0模式。Matrix RAID的原理就是将每个硬盘容量各分成两部分(即,将一个硬盘虚拟成两个子硬盘,这时子硬盘总数为4个),其中用两个虚拟子硬盘创建RAID 0模式以提高效能,而其他两个虚拟子硬盘则透过镜像备份组成RAID 1,用来备份数据。
而nForce3 250Gb芯片组也具有类似的功能,这个功能的新特点就是能够将PATA硬盘和SATA硬盘组成RAID。PATA的硬盘控制器和SATA的硬盘控制器是完全不同的,所以在以前,实现两种硬盘的RAID是绝对不可能的事情。
nForce4 SLI Intel Edition的另外一个突破是采用了双SATA控制器技术。这项技术能够让磁盘的速度达到最佳化。nForce4 SLI Intel Edition的磁盘部分,可以支持多达4个SATA硬盘,但是这4个SATA硬盘是通过两个独立的SATA控制器来运行的,这样能进一步提高性能。
5.8声道音频芯片成为主流
为了提高音频解码的效果,Intel推出了High Definition Audio规范,使声卡所采用的Azalia Link带宽达到了单路输出48Mb/s,单路输入24MB/s(并且可以动态分配带宽),比AC’97所采用的AC-Link的11.5Mps带宽高了很多,这样的高带宽在诸如7.1声道,32bit/192kHz这样的极高数据量工作模式中十分必要。
此外,基于HD Audio 的Codec具有通用总线接口,板载的HD Audio可以使用通用的驱动程序,操作系统就会统一地内置通用HD Audio驱动程序,以往到处找声卡驱动的情况将不会出现(事实上目前的Windows XP和Windows Server 2003最新补丁包已经包含了比较成熟的HD Audio通用驱动程序)。不仅如此,高层面的应用类控制功能也同样得到了统一。
High Definition Audio还具备杜比环绕认证、支持多达16个麦克风、自动感应接入设备、I/O接口功能重定义、多个音频流能在不同I/O接口互不影响地传输、极强的可扩展性等。
二、2005年CPU新技术
CPU一直是硬件系统中发展最快的部件之一。下面就来看看2005年Intel和AMD各自的新技术。
1.采用双物理核心的处理器成为高端
由于单核心处理器的性能逐渐跟不上高端用户的需要,因此Intel和AMD开始使用双核心处理器。
(1)Intel
实际上在双核心桌面处理器出现之前,Intel就开发了“Hyper-Threading(超线程)”技术来提升CPU的多任务处理能力。超线程技术可以把系统中的单一物理处理器虚拟成两颗逻辑处理器,从而提高系统的工作效率。不过,超线程技术只是一种软手段,与真正的双物理处理器相比还是有很大距离的。
Intel目前推出的双核心桌面处理器才是真正意义上的硬双核心处理器,分为两大系列——面向主流桌面处理器市场的Pentium D、面向高端桌面用户的Pentium Extreme Edition。不管是Pentium D还是Pentium Extreme Edition,产品型号都以“8XX”来进行标示。
Intel的双核心架构更像是一个双CPU平台,Pentium D处理器继续沿用Prescott架构及0.09微米工艺。Pentium D内核实际上由两个独立的Prescott核心组成,每个核心拥有独立的1MB L2缓存及执行单元,两个核心加起来一共拥有2MB,但由于处理器中的两个核心都拥有独立的缓存,因此必须保证每个L2缓存当中的信息完全一致,否则就会出现运算错误。

为了解决这一问题,Intel将两个核心之间的协调工作交给了外部的MCH芯片,虽然缓存之间的数据传输与存储并不巨大,但由于需要通过外部的MCH芯片进行协调处理,毫无疑问会对整个处理速度带来一定的延迟,从而影响到处理器整体性能的发挥。
Pentium D和Pentium Extreme Edition之间最大的不同就是对于超线程技术的支持。Pentium D不支持超线程技术,而Pentium Extreme Edition则没有这方面的限制。在打开超线程技术的情况下,双核心Pentium Extreme Edition处理器能够模拟出另外两个逻辑处理器,可以被系统认成4核心系统。
(2)AMD
2005年4月,AMD正式发布了采用双物理核心的桌面处理器——Athlon 64 X2,AMD公司称之为“AMD双核速龙64 X2处理器”。
Athlon 64 X2是由两个Athlon 64处理器上采用的Venice核心组合而成,每个核心拥有独立的512KB(1MB) L2缓存及执行单元。除了多出一个核心之外,相对于目前Athlon 64在架构上并没有任何重大的改变。
双核心Athlon 64 X2的大部分规格、功能与我们熟悉的Athlon 64架构没有任何区别,也就是说新推出的Athlon 64 X2双核心处理器仍然支持1GHz规格的HyperTransport总线,并且内建了支持双通道设置的DDR内存控制器。
与Intel双核心处理器不同的是,Athlon 64 X2的两个内核并不需要MCH进行相互之间的协调。AMD在Athlon 64 X2双核心处理器的内部提供了一个称为System Request Queue(SRQ,系统请求队列)的技术,在工作的时候每一个核心都将其请求放在SRQ中,当获得资源之后请求将会被送往相应的执行核心,也就是说所有的处理过程都在CPU核心范围之内完成,并不需要借助外部设备。对于双核心架构,AMD的做法是将两个核心整合在同一片硅晶内核之中,而Intel的双核心处理方式则更像是简单的将两个核心做到一起。与Intel的双核心架构相比,AMD双核心处理器系统不会在两个核心之间存在传输瓶颈的问题。
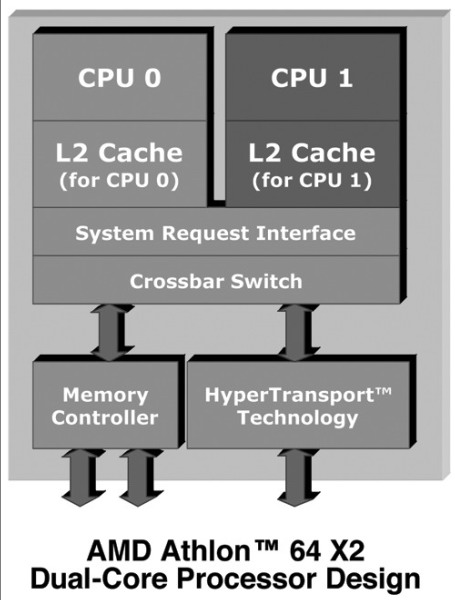
因此从这个方面来说,Athlon 64 X2的架构要明显优于Pentium D架构。
虽然与Intel相比,AMD并不用担心Prescott核心这样的功耗和发热大户,但是同样需要为双核心处理器考虑降低功耗的方式。AMD并没有采用降低主频的办法,而是在其使用0.09微米工艺生产的Athlon 64 X2处理器中采用了所谓的Dual Stress Liner应变硅技术,与Silicon On Insulator(SOI,绝缘体上硅)技术配合使用,生产出性能更高、耗电更低的晶体管。
2.DLS应变硅技术
我们先来谈谈“应变硅”技术,所谓“应变硅”(Strained Silicon),其原理是将硅的晶体拉伸,这样沿拉伸方向电子的迁移率就会提升,导致电阻减小。
DSL类似于应变硅技术,DSL通过向晶体管的硅层施加应力,同时实现了速度的提高与耗电量的降低。换句话说,DSL能改变硅之间的原子格,从而让晶体管获得更快的响应时间及更低的热量。
在一种情况下硅原子是被“拉开”的,而在另一种情况下则是“挤在一起”的,可以通过把它们移到一个具有要么伸展,要么压紧的原子格的氮化物封闭层上来实现。与Intel使用的应变硅不同,来自AMD和IBM的DSL能够用于两种类型的晶体管:NMOS和PMOS(具有n和p通道),无需使用极难获得的硅锗层,硅锗层会增加成本,并且有可能影响芯片的产量。
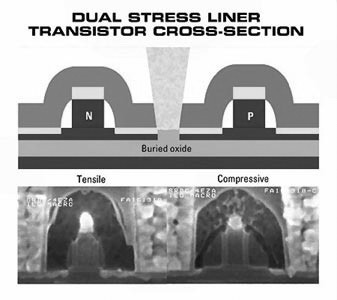
DSL这种双重性,让它比Intel的应变硅更有效:DSL可以将晶体管的响应速度提升24%,而应变硅能提供的最大改进在15~20%。更重要的是,这项新技术对产量及生产成本并没有任何负面影响。由于在生产时无需使用新的生产方法,所以使用标准生产设备和材料便可迅速展开量产。另外,配合使用硅绝缘膜构造(SOI)与应变硅,还可生产性能更高、耗电更低的晶体管。AMD工程师们表示,DSL和SOI一起结合可以让Athlon 64处理器的频率潜力有大约16%的增长。
3.增强型Intel SpeedStep技术(EIST)
EIST是一项自动调节技术,通常存在于Pentium 4 600系列处理器上。Enhanced SpeedStep技术能够根据处理器需要在两种性能模式之间实时进行电压和频率的动态切换。主要是通过切换系统总线频率、内核工作电压以及核心处理器的速度而无需重新进行系统设置实现的。
当Intel将增强型IntelSpeedStep技术引入Pentium 4 600系列处理器时,处理器将自动获得3项新技术——TM2(Thermal Monitoring,热温监控)机制、C1E(增强暂停时态)和EIST技术,这样可以让Pentium 4 600处理器拥有更低的功耗。
如果应用程序需要最大处理器性能,那么处理器频率将会升到它的标称频率,电压也会调回到默认工作电压。启用EIST功能非常类似于Cool’n’Quiet,例如在Windows XP中就有“电源”的设置选项,你必须在“家用/办公桌”选项中将电源设置方案调到最小电源管理模式。这样当处理器不是全负载运行时,处理器将会自动降低它的工作频率。这功能需要操作系统来支持——Windows XP SP2已经充分对此项功能进行支持。
C1E、TM2和EIST三项技术使用一样工作的算法:在空闲的情况下,C1E、TM2和EIST能调节基于采用Prescott E0、Prescott 2M N0核心Pentium 4处理器的倍频。更确切地说,如果需要,基于Prescott、Prescott 2M核心的P4处理器的倍频可降低到14×(这是Prescott核心所支持的最小倍频值),并且核心电压也将下降0.25V。这些总体特征决定的这个扩展模式称为“省电模式”,这时处理器开始运行在2.8GHz频率下同时核心电压也有所降低。
4.Execute Disable Bit技术(XD bit)
为了防止病毒的入侵,Intel和AMD都在硬件层面行集成了防病毒技术,Intel的Execute Disable Bit(XD bit)防病毒功能是与AMD的Enhanced Virus Protection(EVP)相类似,可以防止部分病毒、蠕虫、木马等。这项技术能够保护系统内存数据不会被恶意代码写入和执行,只有在Windows XP SP2系统中才会生效。Execute Disable Bit技术允许处理器根据是否能够执行应用程序代码将内存划分为不同区域,当有恶意的蠕虫病毒试图在缓冲区中插入代码的时候,处理器可以禁止代码执行,从而避免损失并可以防止蠕虫病毒的传播。
所有的Pentium 4 600系列处理器都支持Execute Disable Bit 技术。
AMD所有的Athlon 64处理器在上市之初就已经有类似的功能了,AMD称这个功能为NX(Non-eXecute)或在窗口环境称为EDB(Execute Disable Bit)。而Intel的XD bit安全技术最先应用到频率为3.8GHz的570J型号——Pentium 4 5XXJ。不过,要注意的是:在Windows XP下要安装Service Pack 2后才可拥有此功能,而Windows Server 2003使用者要在Service Pack 1安装之后才有这个功能。
5.增强型64位内存技术(EM64T)
EM64T技术主要存在于Intel的处理器中,该技术是Intel公司自己的64位技术,这项技术和AMD公司的64位技术很相近,支持64位操作系统。目前这两种技术在硬件实现架构上并不相同,不过因为这两种技术使用了几乎相同的指令集,只要在一个处理器上可以运行的操作系统和软件,在另外一个处理器上也可以完全支持。区别在于Intel的EM64T技术支持SSE3指令集和HyperThreading技术,而AMD的处理器无法支持。
三、2005年显卡新技术
作为更新换代最快的显卡,每年都有不同的新技术出现。就2005年而言,显卡所采用的主要技术如下:
1.原生PCI Express×16
PCI Express×16显示接口包括两条专用的通道,一条可由显卡单独到北桥,而另一条则可由北桥单独到显卡,每条单独的通道均将拥有4GB/s的数据带宽,可充分避免因带宽所带来的性能瓶颈问题。同时PCI Express×16接口可以提供更大的电量来驱动未来高性能显卡。
2005年ATi、nVIDIA最终都走到了PCI Express×16原生道路上,但是就目前情况来看,还没有应用软件或者游戏可以充分利用到PCI Express×16的数据传输带宽。
2.SLI技术
SLI的全称是“Scalable Link Interface”,它通过一种特殊的接口连接方式,在一块支持双PCI Express×16的主板上,同时使用两块同型号的PCI Express×16显卡来进行并行处理,从而提高整体的显卡处理能力。
nVIDIA将SLI控制功能直接集成在显卡的GPU芯片内部,在显示芯片中专门有一个很小的区域负责SLI运作,该区域的职能包括两块显卡的连接、通讯,渲染任务的指派以及画面的合成等等。由于指令的传输工作相对简单,在芯片的FCBGA封装中也只有极少几根针脚用于SLI模式。
对于SLI技术,两款显卡的作用并不是对等的。在运行工作中,一块显卡作为主卡,另一款作为副卡,其中副卡只是接收来自主卡的任务进行相关处理,然后将结果传送回主卡,同时两块显卡都是通过PCI-E接口与主板相连接,而这两块显卡之间还要有一个通讯的PCB卡(即SLI桥接卡),其中连接两块显卡的PCB卡用于任务指派指令以及后期处理结果的传送,这部分数据量不是很大,所以PCB卡所使用的接口和自身结构都较为简单。但是,显卡在渲染过程中必须调用大量的数据,这部分数据只能通过PCI-E接口从系统中获取。换言之,在SLI系统中有两部分不同的数据流向,一部分为主卡将任务指令通过PCB连接卡传送给副卡,副卡将渲染完毕的结果数据返回给主卡合成,另一部分为处理过程中从PCI-E接口得到的原始数据。
SLI技术采用帧线方式划分任务,想把一幅画完全渲染出来,这副画面将被渲染分成奇数渲染帧和偶数渲染帧两个部分,然后交给两块显卡分别渲染,完毕之后再统一合成。虽然nVIDIA继续沿用了“Scalable Link Interface”的名号,但在工作的方式上已有了本质性的改变。
奇偶帧数分配也有一些弊端,首先,主显卡或是主GPU必须承担额外的控制、任务分配、画面合成及输出等工作,用于渲染的运算资源较少,但它必须完成与副卡一样多的任务,显然副卡工作效率要比主卡快,副卡率先将自己的任务处理完,把结果数据回传后便处于等待状态,直到主卡将它的任务处理完毕之后才可以继续进行任务出入指派,同时,同一幅画不同区域的复杂度不相同,所需的运算也不一样。
为此,nVIDIA另外开发了一套动态负载平衡技术来解决这一情况,画面的上下划分并不是按照固定的一半一半方式,而是根据画面的复杂情况进行划分,这样的分配并不是为了保证工作量在两块卡间的绝对平均分配,而是要将两块显卡完成渲染任务的时间保持一致,以达到效能的最优化。同时考虑到主显卡需要承担额外的控制任务,用于实际渲染运算的资源较少,动态负载平衡算法就根据这一前提,将任务量多给副卡,来减少主卡的负担,这种动态负载平衡算法并不是集成在GPU芯片内部,而是在驱动程序中整合,nVIDIA可以方便对其进行修改,以达到更好的性能。
3.新型显存共享技术应用
在2005年,nVIDIA和ATi相继在独立显卡上推出了各自的新型显存共享技术——TurboCache和HyperMemory,以便降低低端显卡的生产成本,同时让显卡具备较好的性能。那么这些新技术有些什么特点呢?
TurboCache技术很好地解决了带宽和算法这两个最关键的问题。首先,PCI Express总线实现了远比AGP总线高的带宽,可以有效降低系统延迟,保证数据交换的高速进行;其次,TurboCache可以智能有效地利用内存,当图形核心进行数据的读取和写入操作时可以实时访问内存,而且无需划分固定容量,系统能够根据图形处理工作的需要决定划分或释放内存。
那么TurboCache技术是如何实现智能管理内存的呢?传统的图像处理流程包括几何处理、顶点处理、纹理应用和光栅处理(ROP)。要实现内存的应用,最显而易见的事情是建立从ROP到系统内存的直接通道,这样就可以允许TurboCache直接读取ROP或者从系统内存中直接读取模型缓存,也需要连接像素管线到系统内存的直接通道。
显卡不但需要读取材质缓存,而且还需要材质的动态写出。nVIDIA在GPU中配置了独特的MMU(内存管理单元),在nVIDIA的说明中,MMU可以“允许GPU无缝的分配和不分配系统内存,并且高效地读写内存”。MMU的操作级别非常高,能线性访问系统内存,存储包括纹理缓存、深度缓存、色彩缓存,显著提高内存的利用率。
除了MMU,驱动程序中也针对TurboCache技术进行了相应的修改,实现了以智能化的方式确定色彩、纹理和Z轴缓冲数据的位置。这种处理能力也能够最大限度地提高每种应用的性能。
需要指出的是,目前全双工模式并没有得到Intel新一代芯片组i915/925系列的支持,这主要是由于全双工模式还有一些技术问题尚待解决。nVIDIA最新推出的nForce4系列芯片组很好地解决了这一技术问题,也因此能够实现上下行各4GB/s的传输速率。
利用了nForce4平台的双向PCI Express总线带宽以及显存的带宽,GeForce 6200 TurboCache显示核心能够与系统内存进行上下行各4GB/s的数据交换,并且还能与本地显存通过2.8GB/s的带宽交换数据。
对于系统内存应用的技术,ATi比nVIDIA推出得更早,早在Radeon Xpress200系列芯片组推出时,HyperMemory技术就应用在整合图形核心上。采用Radeon Xpress200芯片组的主板可以集成少量显存存放重要的前台缓存,而其他数据则全部存放在系统内存中。现在,ATi针对nVIDIA的TurboCache技术推出了采用HyperMemory技术的独立显卡。
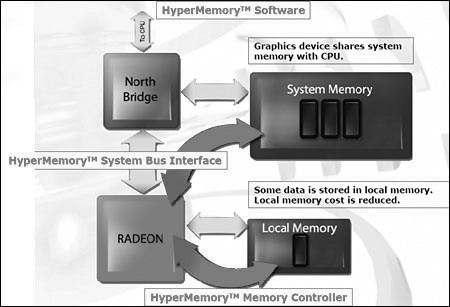
基于HyperMemory技术的Radeon X300 SE HM同样采用了PCI Express图形接口,以保证数据传输的快速。而ATi对于HyperMemory技术的解释就是“一项允许图形卡和CPU共享系统内存,同时将可能出现的性能冲突降到最低的一项技术”,而换成简单的语言来讲,其实就是一项最优化的使用系统内存的技术。
这项技术可以有效提高图形卡性价比:通过HyperMemory技术,图形芯片可以被允许实时访问系统内存,这一点和TurboCache技术没有什么区别,这样,图形卡就可以使用内存作为存储空间,显卡就可以减少本地显存、也就是板载显存的容量,从而达到降低成本的目的。
HyperMemory技术可以从三个主要方面保证在使用系统内存后性能不会有太大的下降,而这一切需要对图形核心和驱动进行适当的改变。这三方面是:{1}HyperMemory系统总线界面采用原生PCI Express系统总线界面,可以保证足够的带宽,确保图形核心更快地访问系统内存;{2}HyperMemory内存控制方法,通过12.8GB/s的高速显示带宽,尽量保证系统内存和本地内存的访问时间相同;{3}HyperMemory驱动,可以对内存进行智能化的管理,让分配存储管理系统和本地内存达到最佳,HyperMemory对内存的管理也是动态的,一旦使用完成,内存可以马上被释放给系统其他应用,确保整体性能不下降。HyperMemory技术驻留在驱动程序中。
没有HyperMemory技术的显卡,显卡核心无权直接访问系统内存,数据交换按部就班地通过北桥芯片完成,显卡需要集成的本地显存非常多,成本同时也很高。这时如果强行降低本地显存而利用系统内存,从显卡核心到北桥芯片、再到处理器去访问系统内存,数据的传输延迟是远远高于本地显存的,这样的结果只会让显卡出现瓶颈,性能大幅度下降。
采用HyperMemory技术的显卡,显卡核心可以直接访问系统内存,从而在图形芯片和系统内存间实现实时的数据交换,显卡只需要集成少量的本地显存,成本可以有效地控制。而HyperMemory智能化的管理可以有效地降低访问系统内存时数据传输的延迟,使其尽量接近本地显存的延迟时间,同时保证内存的分配合理,达到系统和显卡的最佳化,保持性能基本不下降。