另辟蹊径——Cell处理器技术分析
技术大讲堂
2月7日,在美国加利福尼亚旧金山举行的国际固态电路大会(ISSCC)上,IBM、索尼、索尼电脑娱乐公司和东芝公司首次披露了它们联合开发的代号为Cell的微处理器(将会在PS3游戏机上使用)——具有64位计算能力,速度大于4GHz,拥有超级计算机般的浮点计算性能。
这种代号为Cell的处理器被称作System-on-a-Chip(SoC),是一种全新设计的处理器。这个处理器的体系架构有点特别,内部集成了8个特殊用途的SPE单元(Synergistic Processing Elements,协同处理单元)和1个PowerPC处理核心,每个执行单元芯片通过一条高速通道彼此连接起来,组成一个完整的系统,就像是脑细胞通过大脑神经相互联系起来。这样的架构体系和其他处理器相比有什么优势呢?我们下面来看看。
全美达的设计思想
之前,全美达(Transmeta)公司在设计制造Crusoe处理器的时候,采用了“简化处理器的微体系结构并将复杂功能交由软件处理”的设计方案,设计师们认为,为了降低指令潜伏周期和从指令流里写入更多并发指令的技术增加了处理器内部结构的复杂性,这使得本来体积就不大的处理器内核中,用于逻辑控制功能的电路占据了大部分位置,而真正的执行单位却只有很小的一部分。全美达希望把指令重排序等逻辑控制单元从处理器内部全部去掉,将它们的功能交由软件来实现。这样不仅简化了处理器的硬件架构,还可以加快处理器的运行速度。
不过,按照全美达的想法,完全将一些本该处理器实现的功能通过软件去实现,意味着先要将这些功能指令写入内存,再由处理器处理,这无疑会不断增加指令执行单元和内存之间的存储器潜伏间隙(可以简单地理解成指令延时),有悖于最初的设计思想。正因为如此,全美达公司的处理器一直无法有效解决处理器的执行性能问题。
但是,透过Cell处理器,却很好地再现了全美达的处理器设计思想,不过它是从一个完全不同的角度去实现的。与全美达一样,IBM也是以提高微处理器的执行性能为目的,但不同的是IBM认为单一的简化“控制逻辑”单元并不能达到目的,而需要采取其他方法。IBM着手于解决问题的最初阶段,这也恰恰是全美达草率介入的存储器潜伏间隙。可以说IBM对于这个问题的解决方法既简单又复杂:对于处理器核心内部大多数最基本的部分,Cell处理器还是按照以往处理器的设计方法设计,不同的是Cell处理器移动了很少一部分存储器使之更加靠近处理器内部的执行单元,并且让处理器将最常使用的指令和数据存储在这个本地存储器中。
传统处理器的结构
图1展示了微处理器发展过程的三个阶段。第一个阶段的主要特点是静态执行,指令将按照被送入处理器时的精确顺序发布给执行单元。
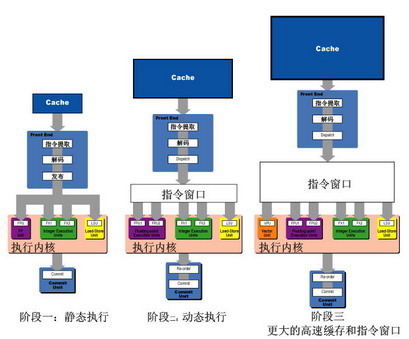
第二个阶段,计算机设计者内置了一个指令窗口,增加了执行核心内执行单位的数量以及增大了高速缓存容量。所以更多的指令和数据可以存入高速缓存子系统(无论是一级缓存还是一级缓存+二级缓存),并且指令可以流入指令窗口,在那里指令将会被分发和重新调度,从而在一大堆执行单元里并行执行。
第三个阶段的主要特点是在适度增加执行核心的宽度的同时,大量增加缓存容量和指令窗口。在这个阶段里,存储器与执行核心相距更远,所以需要更多的缓存来弥补由此带来的损失,以维持处理器性能。同时,由于执行核心宽度的少许增加,造成其执行单元更深(可以理解为更远)的通道传输距离,由此带来的后果就是每个传输周期需要更多的指令去填满更多的执行通道,这将导致指令窗口的大量增加(例如重命名寄存器、重排序缓冲区入口、保留站等等)。与指令窗口有关的控制逻辑电路占据了处理器内的大部分逻辑电路。
这些控制逻辑在早期的静态指令发布RISC系统中只占据了很少的空间。而现在处理器的缓存和处理器的执行内核之间存在着大量的控制逻辑电路(图2)。这些控制逻辑电路占据了大量的核心空间并且增加了通道延时,影响了处理器的执行性能。
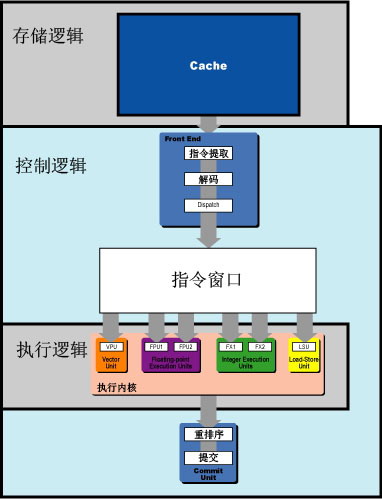
Cell处理器的结构特点
现在,我们来看看单独的一个Cell SPE(图3)。
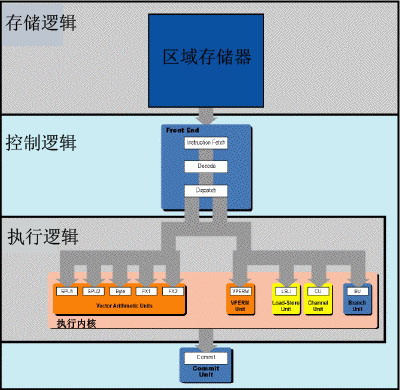
正如你所看到的,Cell处理器已经去掉了指令窗口以及减少用来服务其运转的控制逻辑单元,这有利于增加更多的存储空间和执行硬件。一个Cell SPE并不去处理“寄存器重命名”或“指令排序”这些工作,所以它并不需要“重命名寄存器”存储器或者“排序缓冲器”。
一个单独的SPE和早期的RISC处理器主要存在两点区别。第一,最为明显的区别就是Cell SPE被连接起来用于单精度SIMD计算。大多数的算术指令都是以128位或4组32位的向量格式执行的。所以它的执行核心都是向量运算器而并非传统的定点运算器。第二,也是最为重要的一点,一级高速缓存被一个区域可寻址存储器所替代。我们可以把每一个SPE单元都看作是拥有自己的CPU和RAM的矢量计算机。
这些RAM的功能就如一级高速缓存一样,但它们实际上却受程序员直接控制,这也意味着它们要比一级缓存更为简单。管理缓存的担子完全交给了软件,因此高速缓存的设计简化了不少。SPE也将分支预测和代码调度功能交给了软件处理。
Cell处理器结构特点在于,有8个这样的SPE单元通过中央总线相连,并由一枚PowerPC内核处理所有的常规计算任务,每一个SPE单元仅仅处理各自被分配的任务。
总而言之,IBM运用了RISC的设计思想,抛弃了指令窗口等以换取空间用于放置更多的执行内核,并让更大的存储区域更加靠近执行内核。但不同之处在于,IBM通过一个联合编译器、程序设计器、一些非常聪明的调度软件和一个多用途的CPU来取代传统的编译器(如RISC里的),处理各种调度、资源分配等那些以往由控制逻辑执行的工作。
网络式的工作体系
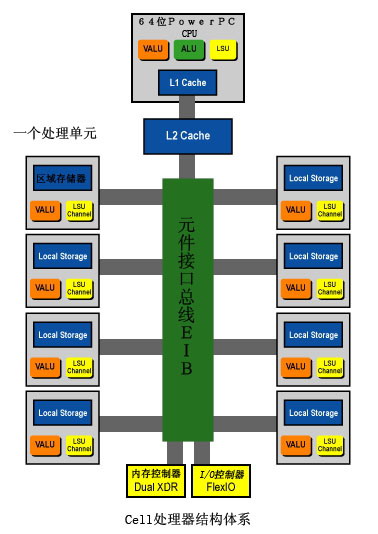
IBM将Cell的最基本的体系描述成“System-on-a-Chip(SoC)”,这种描述的确十分贴切和完美。但我们完全可以更进一步将它描述为“Network on a Chip”,上文已经说到,Cell的8个SPE完全可以看作是8个功能成熟的矢量计算单元,在某种意义上说,它们可以称作是具有各自区域存储器的CPU。这些小的矢量计算单元通过EIB(Element Interface Bus 原件接口总线)与256KB的二级缓存相连。EIB每个周期可以传输96个字节,并可以处理100个以上未完成的请求。
每个单独的SPE可以通过这条总线相互联系,形成一个网络结构,在此基础上,SPE之间进行数据传输(图4)。同样,SPE也是通过这条总线与二级缓存、内存以及系统进行数据传输的。其内置的内存控制器将支持新的Rambus XDR内存。整个Cell处理器采用90纳米SOI工艺,8层铜互连技术制造。拥有2.34亿个晶体管,核心面积约221平方毫米。
总结
通过上面的介绍,我们不应该将Cell单单理解成一枚处理器,应该将它视为一套系统,因为它全新的设计概念已经不能仅仅将它纳入硬件产品,它与软件、网络等等一系列完善的单元构成了一套完整的通用系统,上至服务器/工作站,下至手机/PDA都可以得以运用,相信Cell先进的架构和特性将像我们的脑细胞一样活跃在各个方面。