提高OCR识别效率的诀窍
外设领域
扫描仪用来进行OCR识别录入文字资料已经成了许多个人和单位的扫描仪的主要用途,但是,在进行OCR识别、录入工作的时候,大家一般是按照默认设置来进行扫描的,在这种情况下识别率并不高。如何设置和使用扫描软件才会取得更高的识别率呢?笔者就来给大家分享一下自己的经验。
设置有窍门
图像色彩设定
若仅作文字识别及一般书报黑白插图选取,可将扫描程序的图像色彩设定设置为“黑白”,若设定为默认的“灰度”或“彩色”(这两个模式是为了方便扫描图片,对纯文字识别帮助不大),扫描时间会大大加长,建议不采用这两种模式。
分辨率的设置
设置分辨率越低,扫描速度越快,但因图像质量差,其文字识别准确率低。反之分辨率越高,扫描速度慢,但文字识别准确率高。但这又不是绝对的,因为分辨率设置得太高后,纸张上的微小瑕疵也可能被认作标点符号或汉字“一”等,文字识别准确率反而会有所降低。
经笔者反复测试,分辨率设为300dpi,是扫描速度及文字识别准确率的最佳平衡点。
“输出信息”的设定
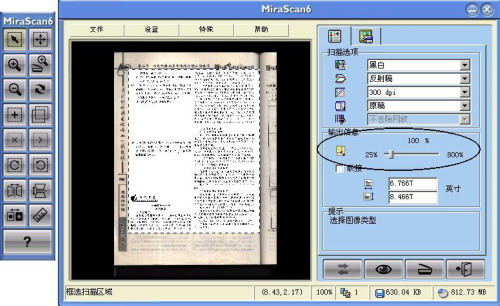
对于常见的打印文件、书、报纸这几种扫描底稿,由于它们的印刷方式和质量不同,原文字颜色可能有深有浅,一般印刷出来的正规书、报和用新色带打印的文件等,“输出信息”项可使用默认的100%。但对文字颜色较浅的文字可适当增大“输出信息”的值,否则扫描所得图像不清晰,文字识别效果较差。
但“输出信息”值也不应设得过大,否则会延长扫描时间且扫描所得图像上的每个字都是一团“黑墨”,不能分辨笔画,文字识别准确率也会大大降低。调整时应注意观察预览图像,做到深浅适度即可(图1)。
自动功能要不要?
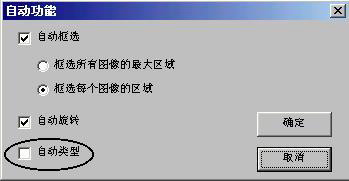
若有多篇的文字需要识别(以常见的尚书6号等扫描软件为例),可点击左侧“设置→自动功能”项打开对话框,去掉“自动类型”前的“√”。否则扫描完一件底稿后,扫描第二件底稿时,前二项设置会恢复到默认值,需要重新设置(图2)。
此外,一些OCR软件带有“一键通”的特色功能,根据笔者的体会,若经常对固定大小、固定格式的原始书刊、文件进行扫描识别,此功能不失为一种较快捷的使用方式,但对不同书、报、文件和不同部位、段落的采集,此功能就不太实用了。
扫描过程要注意
在执行扫描、识别的过程中,一些操作的规范性以及小技巧对于扫描后取得较高识别准确率也是有重要影响的。目前流行的方正OCR、尚书6号、汉王OCR等OCR软件,使用界面几乎完全相同,现以方正OCR世纪版为例进行详细讲解。
扫描操作的要点
打开电脑和扫描仪,将原始文本铺平,将选取文字的一面向下放入扫描仪,文本横放、竖放均可,视纸张大小与选取内容而定(尽可能将文字顶端方向朝向扫描仪无接线的一端,这样扫描出来即为正向的文字),纸张尽量放正,以提高文字识别准确率。
打开OCR软件,单击“扫描”按钮,软件会自动寻找扫描仪。第一次扫描可能要对扫描仪预热,需要等待30~60秒时间,注意使用“图像预览”功能,可用鼠标调整预览图像的虚线框,使之框住欲识别的部分,再单击扫描图标,其它部分则不予扫描、识别,这样可大大缩短扫描及识别时间。
图像处理的要决
扫描完成后,OCR软件会自动打开图像文件,我们需要对它做进一步的调整才能进行文字识别。
扫描所得图像中若文字方向不对,可点击“旋转图像”按钮进行调整,使文字正向。对于底稿中有特殊标记或污点及边缘上不需要的文字可点“擦拭图像杂点”擦除;大面积擦除可点选“擦拭图像块”,注意点选“擦拭图像块”后框选欲删除的部分时,千万不要搞错,OCR软件大多没有“撤销”功能,若不小心将有用部分擦去只有重新扫描了。
图像上只留下有用部分后点击“倾斜校正”,可自动对稍倾斜的图像进行调整。在弹出对话框时,一般点击“是”即可。一般调整角度在±10度以内,若发现对话框中的调整角度明显错误(如89度)则应点击“否”。
文字识别要仔细
文字识别注意顺序
扫描图像修改完毕,还不能急着点击“识别”。
若一页中只选用一部分文字应点“设定识别区域”选择欲识别的文字块,若选择多块文字则注意一定要按欲识别文字的先后顺序依次选取;若全篇文字都要识别可点击“自动版面分析”,对于有插图的或一页中有两栏或多栏文字的排版方式的版面,在点击“自动版面分析”后可能会使识别的文字或段落先后顺序混乱,此时应注意调整文字块的识别顺序:先点击“设定识别顺序”,然后将鼠标移至图像区按欲识别的先后顺序依次点击各文字块,图像上识别顺序箭头会自动调整,调整满意后可点击图像上方的“识别”按钮,完成文字的识别工作。
文字校对不可轻信电脑
文字识别完毕后,软件会自动打开文字校对窗口,各软件出现的窗口形式不尽相同,有的是上半部分为识别后的文字,下半部分是原扫描图像;有的是每行文字下面出现原图像对应内容以方便校对。但应该说明的是,软件通常会把“自认为认不准”的文字采用蓝色文字,“自认为认得准”的文字采用黑色文字,实际上黑色文字也可能出现错误,校对时需要注意。
另外,电脑终究不是人脑,文字识别时“I”和“l”,“0”、“o”和“。”等相似字母、符号的识别经常出错,对形似字符的校对一定要加以重视。
文字输出,选择合理输出格式
文字校对完毕后,点击 “保存”,设置好路径、文件名和格式即可。文字部分可存为文本文件或Word文档,表格最好为.rtf格式,也可保留表格格式。保存后关闭校对窗口。若扫描的图像上有相关插图也想保留,可点击主窗口上方“文件→存储当前图像”,并设定保存路径、文件名加以保存,图像格式一般有.tif或 .bmp,但图像体积较大(若有jpeg格式最好)。保存以后再用“画图”程序或PhotoShop等软件进行详细删改、编辑。
若扫描图像上除已识别文字外无其它有价值的东西则可直接点击“扫描”进行下一页的处理,或点击“关闭当前图像”,在弹出的保存窗口中点击“否”,然后再退出程序。