让内存取代显存——解析TurboCache和HyperMemory显存技术
技术大讲堂
为了保证性能,高端显卡往往配置了大容量的显存。对于低端显卡来说,厂商需要考虑更多的往往是成本高低。而我们消费者关注的是性价比——能以低廉的价格购买到性能强劲的产品。因此,如何在产品性能与成本之间取得一个最佳平衡点,自然就成了当前厂商所面临的问题。不过,随着新一代显存共享技术的出现,这个问题似乎得到了解决……
一、AGP时代的Direct Memory Execute技术
谈到独立显卡分享系统内存,并不是新鲜技术,相信有些朋友一定会想到AGP时代DIME(Direct Memory Execute,内存映射)技术。DIME其实应该是AGP显卡的一大特点,其主要作用是当显卡板载显存不够用的情况下,可以允许显卡利用DIME技术对放置在内存中的纹理进行操作。
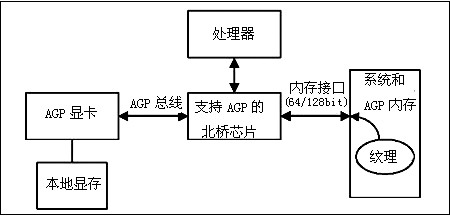
AGP的DIME技术通过显示控制芯片,让主板芯片组对系统内存进行直接操作,利用地址映射方法将系统内存模拟成显存,以用来存储大量的数据(主要是纹理数据)。DIME存取的速度会受到内置在北桥芯片中地址译码硬件的影响。这个内置于芯片组中的硬件称被称为GART(Graphics Address Remapping Table,图形地址再映射表)。
但是随着应用程序对于显卡带宽的需求日益增加,AGP总线出现带宽瓶颈,即便是AGP8×(2.1GB/s)的带宽也不能满足越来越高的数据传输需求,所以DIME的使用非常有限,甚至会降低核心性能的发挥,因此不可能大量依靠系统内存来作为显存。其次在将内存“划为显存”使用上,DIME也存在较大的弊端,内存被固定地划分给图形核心后便不能随意改变,系统难以对这部分内存加以利用,这便造成了内存资源的浪费。最主要的是,DIME只允许显卡在系统内存中存放纹理数据,对于显卡来说操作最多的帧缓存数据却无法通过DIME操作,而目前3D游戏的Shader(顶点着色)、材质贴图、阴影贴图、目标渲染及GPU读取、载入数据等都需要占用缓存空间。如果没有充足的帧缓存,甚至有些游戏是无法运行,即使可以运行也不流畅。因此AGP显卡依然需要配备不少的显存,这也使得显卡成本居高不下。不过随着PCI-E总线的出现,厂商们找到了一个更先进的解决方案:通过PCI-E总线扩展显卡的帧缓存。这也就是NVIDIA的TurboCache和ATi的HyperMemory显存技术。
二、NVIDIA的TurboCache技术
TurboCache的中文名为“智能加速引擎”(简称TC),其最大的一个特性就是支持将图像直接渲染到内存。顾名思义,直接渲染到内存的技术便是通过PCI-E的总线通道,直接对系统内存进行读写访问,而读写的内容便是以往需要用显存来存放和处理的图像数据。
首先需要强调的是,PCI Express ×16的高速总线结构是实现TC内存共享模式的关键所在,如果把GPU比成一个生产基地,系统内存当成一个大型仓库,他们之间必须有一个高效的通道来保证原料的传输。这条“快速通道”就是PCI Express ×16总线架构。当GPU核心有大规模的数据量吞吐时, PCI-E总线高达8GB/s的带宽能保证数据交换顺畅。比如利用nForce4平台的双向PCI-E总线带宽以及显存的带宽,GeForce6200 TurboCache显示核心能够与系统内存进行上下行各4GB/s的数据交换,并且还能与本地显存通过2.8GB/s的带宽交换数据。
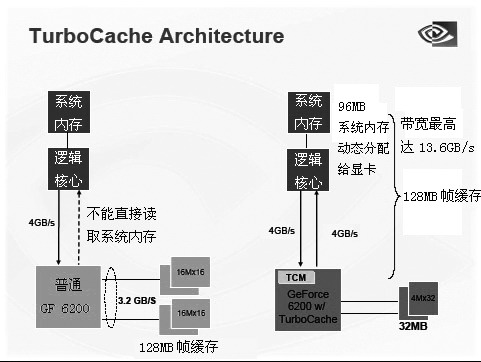
尽管本地显存带宽不高,但是因为TC结构使显卡拥有“双向4GB/s + 2.8GB/s”的数据传输带宽(注意是否能实现双向4GB/s模式还需要看芯片组,比如nForce4平台支持,而i915/925芯片组并不能实现双向4GB/s模式,因此GeForce6200 TurboCache显卡在i915/925的显存带宽最大只有6.8GB/s),因此在总带宽比同级别非TC形式的显卡要高出不少。但我们也要注意到,8GB/s仅是PCI-E供给GPU的带宽,内存提供给显卡的带宽自然无法达到这个数字,因为内存自身有带宽限制,因此采用TurboCache技术上的显卡,实际可利用的带宽是不可能得到理论上的带宽数值的。
由于有足够的带宽,内存与GPU之间的数据交换不存在瓶颈,6200TC实际上占有的“显存”容量很容易实现128MB,无论是看量还是看质,Turbo Cache的规格都要高出其它同级别产品一截。尽管GeForce 6200 TurboCache显卡仍然像传统显卡一样配备板载显存,不过这些板载显存只作为本地缓存之用。在处理3D图像时,本地显存只会保留部分颜色缓存的数据,至于其它的数据,例如Z缓冲、纹理、阴影……等,都可以存放在系统内存中通过PCI-E ×16通道随时调用。与传统的DIME不同,TurboCache对内存的实时调用不需要划分固定容量的内存,系统能够根据图形处理工作的需要动态访问内存,这也是TurboCache技术的一大特点。
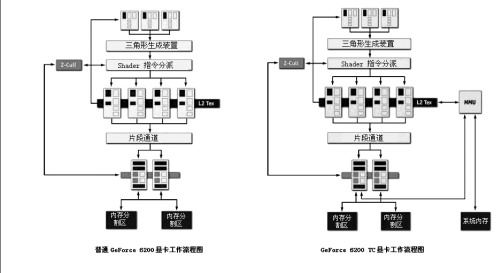
由于主内存与显卡本地显存之间存在一定的距离,再加上内存速度的限制,GPU从系统内存读取或储存数据时需要花费更多时间,这样存在一个延迟问题。比如在普通GeForce 6200的渲染工作流程中,NV43的4条渲染管线和2组内存分区之间并没有直接的连通,绝大多数的流程箭头都是向一个方向,说明数据流的处理方式也是单一性的。一旦需要渲染的材质过大,数据超出本地显存的负荷,GPU核心必须在系统主存和本地显存、显存和GPU逻辑结构的通信交换中等待,自然会出现时间上的浪费。
针对这个问题,NVIDIA在TurboCache架构中引入了称为“MMU(Memory Manage Unit,内存管理单元)”的功能。系统主存通过MMU直接和渲染引擎部分交换数据,同时调用和动态地分配本地及系统内存容量,把本地显存和分配到的系统内存浑然视作一体。在材质渲染引擎部分,系统主存通过MMU控制单元,直接接受管线的数据寄存调配,显存只承担了后期显示输出的基本渲染工作,工作量也小很多了。GPU通过MMU和PCI-E总线和主内存进行读取和写操作,自动把渲染结果和纹理分配在本地显存或者系统内存上,以较少的本地显存实现比其它同价位不具备此能力的产品更高效率的内存管理机制。
当然,TurboCache技术对系统内存也有一定要求,系统内存不宜过小。如果系统使用512MB以上的内存则可完全发挥TurboCache应有的水准,如果只安装256MB系统内存,那么TurboCache可使用的内存则会减半。例如32MB版本的GeForce 6200 TurboCache显卡理论上可以使用96MB的内存(32MB本地+96MB内存=128MB),如果电脑只装256MB,那么TurboCache可用的系统内存会减少到32MB。
可以说,TurboCache是一种比较经济的低端解决方案,由于主存和显存之间数据交换存在延迟和中断的问题,因此TurboCache方案的效率肯定不如理论数字来得那么理想,在某些方面与完全板载显存的显卡相比还是会有性能上的差距。
三、ATi的HyperMemory技术
面对NVIDIA的TurboCache技术,ATi也祭出了自己的杀手锏——HyperMemory技术。两项技术有许多相同之处,都能够动态地从系统内存中存储和调用显示数据,从而达到分享内存提升显示性能的目的。当然这一切需要对图形核心和驱动进行适当的改变。
基于HyperMemory技术的Radeon X300 SE HM同样采用PCI-E图形接口,以保证数据传输的快速。同时像TurboCache技术一样,基于HyperMemory技术的显卡如果在板载显存不够用时,图形核心也可以通过12.8GB/s(双向4GB/s + 4.8GB/s)的高速显示带宽直接调用系统内存。不过这样虽然保证了显卡的速度,系统所能使用内存的数量和速度都会相应受到影响,所以ATi并没有提倡完全放弃板载显存——HyperMemory架构像TurboCache技术一样仍采用“板载显存”+“系统内存”作为“显存”。
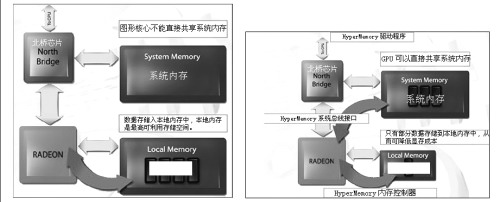
我们在前面已经提及,在传统显卡渲染过程中,当板载显存不够用的时候需要借助DIME功能调用系统内存,但图形芯片无权直接访问系统内存,数据交换都需要通过北桥芯片完成,从图形核心到北桥芯片、再到处理器去访问系统内存,数据的传输延迟是远远高于本地显存的,这样的结果只会让显卡性能大幅度下降。显卡需要集成的本地显存非常多,成本同时也很高。
采用HyperMemory技术后,由于图形芯片和系统内存间可实现实时的数据交换,显卡只需要集成少量的本地显存,成本可以有效地控制。而通过HyperMemory驱动的智能化管理可以有效地降低访问系统内存时数据传输的延迟,使其尽量接近本地显存的延迟时间,同时保证内存的分配合理,一旦使用完内存后可以马上释放给系统作其它应用,达到系统和显卡的最优化,保持性能基本不下降。
虽然HyperMemory技术不错,但也有值得改进的地方。某些情况下,如果选择了在本地显存存放帧缓存的时候,就无法直接往系统主内存再保存帧缓存 ,而需要先保存在本地后再往系统内存传递,这时效率会降低。因此系统内存仅包含纹理数据,其它的绘图数据依然存放在显卡的本地缓存中,不过本地显存的容量(一般板载显存只有32MB)往往是无法满足某些3D游戏需要的,这意味着HyperMemory技术在某些大场景的游戏中发挥会受到影响。
目前ATi计划推出两款基于HyperMemory技术的显卡:Radeon X300 SE 128MB HM和Radeon X300 SE 256MB HM,两者都采用Radeon X300 SE芯片,核心频率都为350MHz,显存的频率也都为600MHz,两者的主要区别在显存规格上。Radeon X300 SE 128MB HM集成2片BGA封装的本地显存,64bit显存位宽,容量为32MB;而Radeon X300 SE 256MB HM集成4片TSOP封装的本地显存,组成64bit的显存位宽,容量为128MB。因为采用HyperMemory技术的Radeon X300都只有64bit的显存位宽,所以在名称后面都有SE的后缀。
结语:
不难看出,从制造成本来看,此类动态分配系统内存的应用降低了显卡板载的显存数量,让显卡整体的成本进一步降低,这将对目前的板载整合显卡造成极大的威胁。重要的是它们可以大大降低进入PCI-E平台的门槛,更能有效地促进PCI-E平台的普及。
同时我们也要留意的是,从性能来讲,由于主存和显存之间数据交换存在延迟和中断的问题,同时硬件系统的千差万别,包括内存容量、芯片组等都可能会导致图形性能表现出巨大差别,因此TurboCache、HyperMemory方案的现实性能与理论值还是存在一定差距的。故ATi更偏向于将这项技术应用在整合主板上,在独立显卡应用观点上仍保持了比较慎重的态度。NVIDIA虽然首先将TurboCache应用到了独立显卡上,但它也一再强调配置大容量内存是相当必要的,要想充分发挥具有TurboCache技术的显卡的性能,用户应尽量采用大容量、高频率、双通道内存,这样无形中又会增加内存的采购成本——这个问题在电脑选购中不得不考虑。
TurboCache和HyperMemory方案是否能为市场、用户接受,还需要时间来证明……