贫嘴M牛的网络生活──在线巧识别 工作好轻松
网络通信
这天,贫嘴M牛突发奇想,想把心爱的《电脑报》做成电子书保存在自己的电脑中,方便今后查阅。可《电脑报》九大版块108版,手工录入显然是匪夷所思,想来想去,还不如把报纸扫描成图片,拿到免费文字识别网上OCR一下。
成为会员
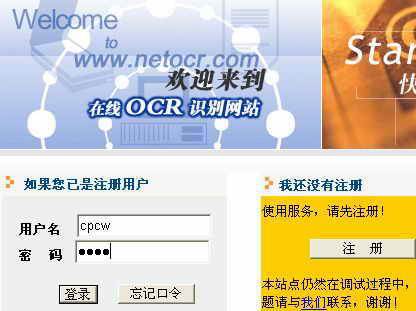
OCR识别系统应用了清华大学电子系研制的一种用来从图像中识别出文本字符的技术。要想运用该技术,可以安装正版的OCR软件或是使用网站提供的免费识别服务(图1)。首先必须注册成为该网站的会员。在浏览器里输入“http://www.netocr.com”,打开首页,点击“注册”按钮进入注册页面,填入各项相关内容后就可以轻松完成注册。注册完成后回到首页,填写用户名、密码等,登录到用户文件管理页面(图2)。
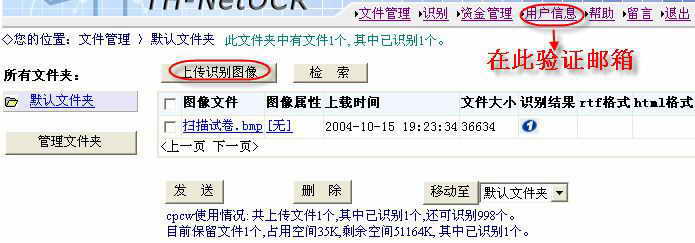
每个合法的注册用户可以免费在线识别999幅图像,但提交的识别图像总的空间不能超过50MB,一天之内也不能超过99幅图像。所以我们要经常删除自己储存在“默认文件夹”中的图像文件,以免超过50MB。
M牛提示:“邮箱”一栏中务必填写自己的正确的电子信箱地址,因为今后网站会将你选择的特殊格式的识别结果发送到你的信箱,并且会发送一封验证信件到你的电子信箱,内含验证口令。
验证邮箱
为了享受更好更周到的服务,建议你验证自己的邮箱。方法是:单击管理页面中“用户信息”,然后在“用户详细资料”下单击“验证邮箱”按钮,然后输入验证口令再点击“验证”按钮便可。
上传识别
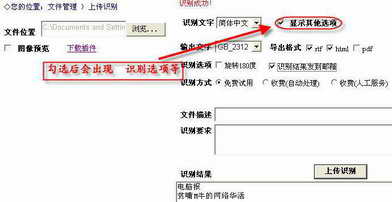
准备好自己需要OCR的图片文件,扫描得到的图像要清晰可辨,分辨率越高识别效果越好,所以要尽量提高分辨率。单击管理页面中的“上传识别图像”按钮,进入“上传识别”页面(图3),点击“浏览”按钮,选择储存在硬盘中的图像文件,而后选择好需要识别的文件语言、识别要求等选项;还可以勾选“显示其他选项”,在其中对输出的文字编码、文件格式、识别方式等选项进行设置。在这里M牛为了做HTML的电子书,特地勾选了“导出格式:html、识别结果发到邮箱”,这样就可在自己邮箱内收到扫描识别后的网页文件了。最后单击“上传识别”按钮,片刻后会在“识别结果”下的方框内输出识别的结果。
M牛提示:在线OCR仅支持TIFF、BMP、JPEG格式图像的识别。建议你在识别之前将自己的文件转换成相应的文件格式,推荐使用JPEG格式的图像。
取回果实
辛苦了半天,终于看到了自己需要的文本内容,现在要做的就是要将这些宝贵的资料复制保存下来。在“识别结果”文本框内的文字是纯文本格式,你可以用鼠标选中自己需要的文字,再“复制、粘贴”到Word或其他软件中。如果已经在第二步中验证了自己的邮箱,并且勾选了以HTML、PDF格式导出,就可以在两小时后到自己邮箱里取回自己的资料了。
M牛提示:由于图像不清或网络原因,识别结果可能与原文有部分出入,你可以在复制出文字后在其他软件中进行校正更改。