SQL之恋(7):用户定义函数,SPROCS“变种Ⅰ”
软件世界
上次我们认识了存储过程(SPROCS),了解了它的优势所在,也了解了它的“致命伤”──不能与SELECT、UPDATE等语句结合。为了解决这个问题,SQL Server提供了一种SPROCS的“变种”──用户定义函数。
引子
大家一定还记得上次(第5期E14版)我们一起为NorthWind数据库编写的存储过程 SalesByCategory_TEST。它的作用是返回反映指定年份、指定类别产品销售情况的结果集。这个结果集包含两个字段,分别是ProductName(产品名称)和Total Purchase(总销售额)。
如果现在需求有变化,除了ProductName和TotalPurchase之外,我们还希望得到产品的CompanyName(供应商信息)。熟悉SQL语言的朋友最先想到的解决方案也许是这样的:把SalesByCategory_ TEST 返回的结果集与Products表和Suppliers表进行连接。
--注意:此代码 SQL Server不支持!
SELECT C.CompanyName,A.* FROM (EXEC SalesByCategory_TEST 'Beverages',DEFAULT,'') A
INNER JOIN Products B ON A.ProductName=B.ProductName
INNER JOIN Suppliers C ON C.SupplierID=B.SupplierID
很遗憾,SQL Server不支持存储过程与SELECT-SQL 的联合使用。所以上面的代码在SQL Server里是不被支持的。
“隔靴搔痒”的尴尬
就问题本身来讲,在不修改存储过程的前提下,我们还可以这样处理:利用INSERT INTO…… EXEC结构把存储过程返回的结果集送入临时表中,然后取得结果。代码如下。
--建立临时表 #TEMP
CREATE TABLE #TEMP(ProductName nvarchar(40),TotalPurchase money)
--把存储过程返回的结果集插入临时表
INSERT INTO #TEMP (ProductName ,TotalPurchase) EXEC SalesByCategory_TEST 'Beverages',DEFAULT,''
--得到需要结果
SELECT C.CompanyName,A.*FROM #TEMP A
INNER JOIN Products B ON A.ProductName=B.ProductName
INNER JOIN Suppliers C ON C.SupplierID=B.SupplierID
--删除临时表
DROP TABLE #TEMP
上面的这种解决方案给人一种“隔靴搔痒”的感觉,不爽。我们还是希望直接把存储过程返回的结果集在SELECT-SQL 中使用。解决方法就是使用存储过程的“变种”──用户定义函数。
“一气呵成”的感觉
在SQL Server 2000中增加了被称为“用户定义函数”的新特性,之所以称作“用户定义函数”,是为了区别于SQL Server自带的内置函数。它给我们带来了什么呢?那就是“一气呵成”的感觉。针对同一个问题,我们可以创建如下的用户定义函数udf_SalesByCategory_TEST:
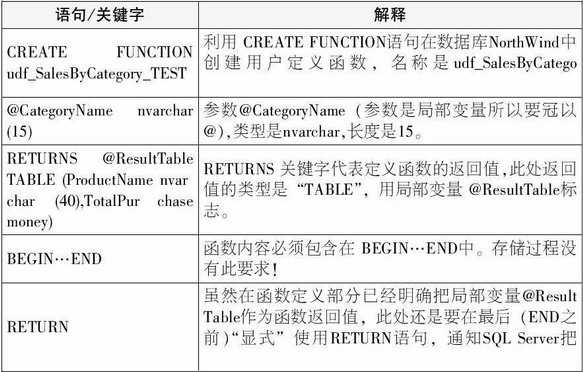
--创建用户定义函数
CREATE FUNCTION udf_SalesByCategory_ TEST(@CategoryName nvarchar(15), @OrdYear int= 1998)
RETURNS @ResultTable TABLE(ProductName nvarchar(40),TotalPurchase money)
AS
BEGIN
IF @OrdYear != 1996 AND @OrdYear != 1997 AND @OrdYear != 1998
BEGIN
SELECT @OrdYear = 1998
END
INSERT INTO @ResultTable
SELECT ProductName,TotalPurchase=ROUND(SUM(CONVERT(decimal(14,2), OD.Quantity * (1-OD.Discount) * OD.UnitPrice)),0)
FROM [Order Details] OD, Orders O, Products P, Categories C
WHERE OD.OrderID = O.OrderID
AND OD.ProductID = P.ProductID
AND P.CategoryID = C.CategoryID
AND C.CategoryName = @CategoryName
AND DATEPART(YEAR,O.OrderDate) = @OrdYear
GROUP BY ProductName ORDER BY ProductName
RETURN
END
GO
相关代码的分析如下:
现在我们看看用户定义函数如何与SELECT-SQL完美结合:
--注意函数的调用方法
SELECT C.CompanyName,A.* FROM udf_SalesByCategory_TEST('Beverages',1997) A
INNER JOIN Products B ON A.ProductName=B.ProductName
INNER JOIN Suppliers C ON C.SupplierID=B.SupplierID
其他类型
在SQL Server 2000中支持三种用户定义函数。前文讨论的udf_SalesBy Category_TEST属于“多语句表值函数”。所谓“多语句”是指函数体包含多条T-SQL语句,“表值”是指函数返回数据集(在SQL Server中也可以理解为“Table”)。其他两类用户定义函数见下表。

谁更“强悍”
用户定义函数可以和SELECT-SQL语句结合使用,突破了存储过程的限制。不过,朋友们千万不要就此认为用户定义函数比存储过程更强更好,因为用户定义函数还有很多限制。
●最明显的是用户定义函数只能返回一个值(表或标量),不支持输入输出参数。而存储过程除了具备整型返回值之外,还可以返回多个结果集,另外通过输入输出参数还可以传递大量的信息。
●用户定义函数的函数体(即BEGIN和END之间的语句)不能有任何“副作用”。所谓“副作用”是指不能对用户定义函数体之外的任何资源作永久性的变更,比如修改数据库中表的数据。
这个限制是致命的:有系统开发经验的朋友都知道,我们经常在存储过程中实现复杂的逻辑。例如会计月末结账,需要更新表中很多数据,有时候甚至需要建立、删除表或修改表结构,这些操作在用户定义函数中都是绝对禁止的。
●用户定义函数的返回值必须“确定”。如果任何时候用一组特定的输入值调用函数时返回的结果总是相同的,则这些函数就是“确定”的。
总之,用户定义函数不是存储过程的替代品,朋友们必须根据它们提供的功能和各自的限制,结合实际需求,择其善者而用之。
下次我们讨论存储过程的另一个“变种”──触发器。