文字录入化繁为简
整机外设
OCR(光学字符识别)的出现,让那些成天为了对付成堆的录入稿发愁的朋友不再烦恼。把文字稿扫描成一张张的图片再利用OCR识别软件进行识别,最后再进行个别字符的修改,一篇漂亮整齐的稿子就录入完毕了。这一技术的出现使得办公效率大大提高,不过有些朋友可能还不太会使用,其实OCR使用起来很简单。下面笔者就介绍一下这类软件的使用技巧,希望可以帮助那些使用OCR软件的新手。
我们以清华紫光TH-OCR2000版为例,启动该软件,进入主界面,该软件主要分为两大区域,左边是预览区,右边是识别操作区,识别操作主要就是在这个区域进行的。
1.识别前的准备工作
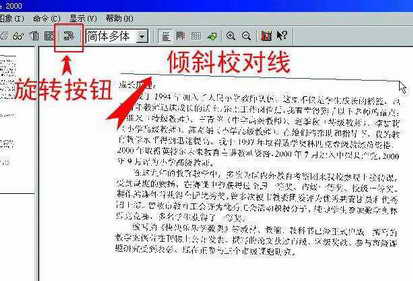
通过扫描获得一张图片,该软件就会把该图片的缩略图放在左边,正常显示的图片在右边,以便于识别。下一步,把图片尽可能地调整为正四边形,这样识别率会比较高。你只须像在Photoshop里画线一样,在起始点按住鼠标右键并拖动鼠标,使这条线尽量与文字行平行,达到一定距离后松开鼠标右键,文字便会自动进行校正。有时会碰到图片倾斜角度大于90度的情况,就可以使用旋转90度按钮“”配合手动操作进行调节(图1)。
2.一扫而过
校正完成后,就可以开始识别了。在识别之前还有一项非常重要的工作──选择语言种类,如果原稿是一篇简体中文,就选择“简体多体”,如果是一篇英文稿件就应该选择“纯英文”,此项选择有助于识别正确率的提高。接下来拖动鼠标,将要识别的文字或文字块用线框框住,如果不止一个文字块,依次框选即可。在此笔者提醒大家,识别的顺序应该和阅读的顺序保持一致,否则很容易出现识别错误(图2)。识别框选取完毕后,点击识别按钮“”或按F2键就可以开始识别了。

提示:有时会遇到横排、竖排同时出现的文章,大家可以点击横排、竖排按钮进行识别框类型的变换,横排识别框为蓝色,竖排识别框为红色。
3.查漏补缺
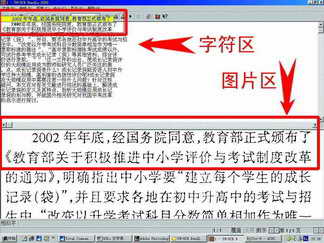
稿件识别后就会进入修改界面(图3),界面上方为文字区,下方是对应的图片。将光标移动到段落的某个位置,那么下面的图片也会移到相应的地方,该软件这样设计的目的就是为了让使用者能对照原稿进行修改,因为OCR软件毕竟不可能百分之百地识别正确,还需要人工修改一些小地方。修改完成后点击存盘按钮就可以保存了。
提示:笔者曾经遇到过这种情况,几篇被识别并修改好的稿子一下子恢复成原样了。几经查证才知道是同事不小心又重新识别了一遍,修改后的文件就被覆盖了。所以笔者建议大家在最后修改完成后把文字拷贝成一个新文本文件,这样就可以防止被覆盖。
4.清理现场
识别工作完成后,就可以退出软件了。不过你一定要记住清理现场留下的“垃圾”。因为该软件在识别时会产生扩展名为“SIM”、“CHR”、“TRC”的临时文件,只要大家在退出软件时显示的提示框中勾选“删除”,那么在扫描的目录里就只会剩下干干净净的文本文件了。