与显卡的亲密接触
整机外设
前 言
如果要问当今硬件市场最火热的产品是什么?发展最快的产品是什么?答案既不是飞速前进的CPU,也不是日新月异的内存或主板,这顶桂冠非显卡莫属。
我们为什么要显卡?
说到显卡,它属于计算机的输出设备,是承担人机交流的必要载体,是电脑必不可缺的核心部件。但是,在电脑诞生之初,是没有显卡这个部件的,当时人机之间的交流是通过打孔机来进行的。打孔机通过在纸带上打与不打来代表二进制的“1”与“0”,人们再通过这些二进制数据得到所需信息,所有的信息都是通过那枯燥且堆积成山的纸带传递的。这种二进制的人机交流实在不符合人们日常的语言习惯,因而很难适应。所以当键盘和显卡,显示器这些更加亲和的输入输出设备出现后,打孔机迅速被淘汰。而且随着图形操作系统如Windows, MAC OS X等更加华丽的系统界面的应用,以及已经雄霸天下的三维游戏的需要,显卡已经发展为独立的图形处理器,在整个系统中的责任也是越来越大了。
对于显卡这个大功臣,很多朋友却只是知道它的名称或者仅限于有多大显存而已,而对于它的其余种种特性,却不是很了解。那么希望通过本文,能够使大家与现有的显卡以及相关的显示技术有一次亲密接触。
显卡的构造
显卡是什么?“就是电脑中负责输出显示信号的配件”,“就是那个能让我玩3D游戏的东西么!”……大家的回答可能多种多样,虽不够严谨,但是却也说得出一二。那么显卡是什么样?虽然大家天天都在和它打交道,兴许你还的确不知道显卡的模样,或者仅仅是购买电脑时瞧上两眼而印象不深。那没关系,这就让我们从机箱中把它请出来,让各位好好端详一番(图1):

图1中的主人公就是如今的显卡之王,NVIDIA最新NV30核心的GeForce FX5800 Ultra(上)和Quadro FX2000(下)。怎么样,没想到终日默默无闻工作的显卡看起来竟如此气派和有艺术感吧?或许你的显卡和它们不相同,但那仅仅是外观和性能上的差别,而显卡的基本结构是相同的。那么就让我们通过它好好看看一块显卡的里里外外。OK!正面已经露了,那再给大家一幅背影(图2)。

看了这两幅照片,我想大家印象最深的可能是那拥有巨大风扇的散热器系统。风扇下面到底是何方神圣?让我们揭掉风扇看个明白。
显卡需要核心
风扇下面就是显卡的核心芯片(图3),如同电脑的CPU一样,它现在已经被芯片设计者叫做GPU(图形处理器)了,其运算能力和芯片负载程度与中央处理器相比已是不遑多让。显卡的核心芯片是显卡的心脏,显卡的性能如何大半都是由它决定的。而我们平时选购显卡时所说的型号,通常也是以显卡核心的名称来命名的,如GeForce4 Ti4200、ATi 9100等。目前市场主流的显卡芯片主要是以下几个系列:NVIDIA公司出品的面向家庭的GeForce系列和面向专业图形工作站的Quadro系列,以及与NVIDIA针锋相对的对手ATi的Radeon(镭)系列和同样面向专业图形工作站的FireGL系列。除此之外,还有SiS的Xabre系列、Matrox的G系列等等。

也许有的朋友看到这里后,就想打开机箱看一看自己的显卡的芳容,结果却发现找不到类似的卡,定会纳闷:我的电脑没有显卡又是如何出现图像的呢?其实,你的显卡属于整合显卡,它已集成在主板上。当前,整合显卡也是市场的主力军,它们与独立显卡分庭抗礼,由于成本低廉、稳定性好等原因,特别受到OEM厂商的青睐。主流的产品有Intel整合在i845家族中的Extreme显卡,VIA整合在PM、KM系列芯片组中的Savage显卡以及SiS整合在SiS650/630/740系列中SiS315显卡。这些整合显卡的性能虽然比不上主流的独立显卡,但对于一般用户上网、办公,玩玩简单的三维游戏却已足够了。
现在的显卡被称为GPU,先得益于其所拥有的强大几何运算能力。与繁忙的CPU不同,显卡的所有单元都只进行图形运算。原本三维运算的T&L(几何转换和光影处理)是由CPU来完成的,但是自从NVIDIA开发出了划时代的GeForce256以后,现在连T&L也尽数被显卡接管了。称显卡芯片为GPU是名副其实的。
当我们的显示画面千变万化时,其流程都是由中央处理器把各种相应的指令下达给显卡,而由显卡调用各种运算函数瞬间完成后呈现给我们的。这种运算过程基本不需要中央处理器辅助的,而这种图形函数的加速运算就是平时DIYer们所说的硬件加速。无论二维还是三维,现在的显卡都有一套相应的完整的运算函数相对应,用来应付各种日益加重的图形处理任务。具体的介绍我们放在后文,现在我们接着看显卡的构成。
显卡需要显存
如图4,这就是显存,它是显卡的重要组成部分。如同计算机的内存一样,显卡的显存也是用来储存要处理的图形信息的必要场所。我们在显示屏上看到的每一点像素都以4至32甚至64位的数据来控制它的亮度和色彩,这些数据必须通过显存来保存,再交由显示芯片和中央处理器控制调配,最后把运算结果转化为图形信号输出到显示器上。

对于现在的显卡来说,显存是承担大量的三维运算所需的多边形顶点数据以及作为海量三维函数运算的主要载体,因此,显存的交换量大小、运行速度的快慢对于显卡核心效能的发挥都是至关重要的,而如何有效地提高显存的效能也就成了提高整个显卡效能的关键。打个比方说:显示芯片是一辆快车的话,那么显存就是它的奔驰的道路,再快的高级跑车在泥泞小道上也无法急驰,只有在机场般宽敞高速的大道上才能尽情驰骋。
显存伴着显卡一路走来,历经DRAM再到SDRAM以及现在主流的DDR SDRAM,显存的速度已是越来越快。但是,目前越来越复杂的三维应用需要更快的显存。因此,NVIDIA公司采用了速度高达1GHz的DDR Ⅱ显存(就是你在右图中看到的这种),而ATi则另辟蹊径,采用了高达256bit位宽的显存。这两种方法的优劣,我们在后文剖析显存技术时会有分解。正因为显存对于显卡的整体效能会产生巨大影响,开发商们便利用同样的显卡核心搭配不同速度或者带宽的显存来区分显卡产品的高中低端。例如ATi的镭9700和镭9500PRO,核心同样是R300芯片,运行频率也一样,只是因为镭9700搭配了256bit的显存,而镭9500PRO却仅仅只有128bit,这就直接造成了图形运算中表现出来的巨大差距!小小的显存,竟成了扼住GPU脖子的杀手,其重要性可见一斑。
对于采用整合显卡朋友们,显存很可能会从系统内存中划拨。这也曾让很多朋友纳闷:我的256MB内存,为什么系统只显示了255MB甚至224MB或更少?答案很简单:它们被划拨过去做显存了!相对于独立显卡来说,调用系统内存一来会争抢本来就捉襟见肘的带宽,使得计算机整体性能有所下降,二来就算是采用DDR400的系统内存,也仅仅只有可怜的64bit位宽,同一时间内所能提供给显卡的数据量同独立显卡相比是遥遥落后的,而这两点都是目前制约整合显卡性能的致命伤。
小知识
主流显卡芯片的制造工艺
和CPU一样,显卡的核心芯片,也是用硅片制成的。那么积极提升制造工艺,对于提高显卡的集成度和运行频率是必不可少的。更重要的是制造工艺的提高可以有效地降低显卡芯片的生产成本。所以在最新的GeForce FX系列显卡芯片上,NVIDIA已经采用了和CPU相同的0.13微米制造工艺,集成了高达1.25亿个晶体管并且拥有高达500MHz的核心频率!采用0.13微米制造工艺的好处显而易见:一方面可以提升晶体管的转换速度,另外一方面,与普遍采用的0.15微米制造工艺相比,0.13微米制造工艺可以有效地降低图形芯片的功耗和发热量。而且,0.13微米制造工艺也使得在更小的芯片面积当中封装更多数目的晶体管成为可能。但因为制造工艺转换难度巨大,所以即使是ATi最新的R300核心,也只有暂时采用0.15微米制程。
显卡需要系统接口
显卡作为整个系统的一部分,是怎样和系统连接的呢?看到图5中那排金手指吗?那是显卡的与主板的连接接口(当然主板上有与之对应的插槽),你可不要小看这接口,它不但是显卡和整个系统的连接界面,同时也是显示子系统和整个系统之间唯一的联系通道,大量的数据交换都是通过这个接口完成的。这个接口同时也负责显卡的供电工作。

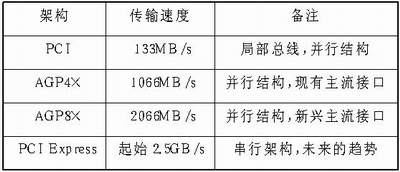
显卡与系统的接口也有多种类型,图5中这种接口的架构叫做AGP架构,这是目前的图形界面和主系统的主流接口。以前,显卡与系统之间的交换是通过标准的PCI甚至ISA总线来进行的,不过随着图形处理的数据量日益增加,这两类总线已经无法满足需求了,于是就诞生了AGP这个廉价的解决标准。现在的AGP工作模式已经达到了AGP 8×,理论传输带宽已经达到2.13GB/s,只可惜即使如此,在三维运算动辄就需要数十GB/s的流量面前,也是杯水车薪。为了解决AGP结构相对低下的效能,一来显卡设计厂商将三维运算数据尽可能地只在显卡的本地显存中完成,不通过AGP这个瓶颈;二来尽快过渡到英特尔所倡导的更快的PCI Express总线,这也是未来显卡发展的必经之路。再说整合,虽然很多整合显卡所在的主板是没有AGP插槽的,但是整合的显卡和主系统之间的数据交换也是通过AGP总线,只是你看不到罢了。
各种显卡所用接口性能比较
显卡需要供电
图6所展示的是显卡的供电电路。随着显示芯片功能的日益强大,虽然我们看到的最终画面是越来越精美,但是给整个显卡的供电和散热的负担也越来越重。为了稳定工作,保证良好的图像输出,优秀的供电电路必不可少。一块显卡供电单元的设计优劣,除了直接决定了一块显卡能否在高频下稳定工作,也关系到显卡的超频性能。

而对于最新的一代显卡例如Radeon 9x00系列和GeForce FX系列,AGP规范中额定的供电已经不能满足它们稳定地工作的需要,只凭主板自带的AGP插槽已经无法满足显示芯片的供电需求,虽然像华硕等大厂都在主板上使用AGP PRO插糟来辅助供电,但是一般来说只有面向专业市场的显卡才会采用这个AGP PRO标准接口。所以我们就在新一代面向家用的显卡上重新看到了熟悉的硬盘或者软驱所用的供电接口,通过这个接口,显卡直接从主电源取电。使用时一定要接上这个电源,因为如果忘了,兴许买来的最新显卡根本就无法开机(ATI系列显卡忘接电后的结果)或者是虽可使用但是变得很慢(NVIDIA系列卡忘接电后的表现)。
好的显卡在供电部分都是不惜工本的,如图6中所示,整个供电系统采用了大量高品质的电容和扼流线圈,起到稳压、滤波和变压的作用。当然除了这些以外,还有一个部分对于整个显卡的供电系统也是很重要的,那就是供电电路的控制IC。如图7,这个小小的IC负责管理整个供电模块,一块设计优秀的IC,可以精确地平衡各相电流,维持功率组件的热均衡,即保证了系统的稳定性,又使显卡可以完全发挥出其性能。

对于一个想进行极限超频的DIYer来说,选择显卡的时候一定要对于供电模块仔细考察,那些偷工减料的产品千万要敬而远之,因为那样的产品可能连显卡正常工作的稳定性都不能保证,更何论超频呢!
显卡需要散热
以前的显卡工作时发热量很小,所以只要芯片裸露或者仅仅加一个散热片就行。但是现在不同了,动不动就是几千万晶体管集成在那个方寸的核心上,电路极其复杂,而工作频率也已经高达500MHz。而为了保证整个显卡的稳定工作,为显示芯片安装相应的散热风扇是必需的。而且因为显卡的工作空间不像CPU那么充裕,所以对于散热系统,特别适用于高端产品的散热系统的要求也越来越高。图8的散热系统是目前显卡中的佼佼者。不过后遗症也有,一是散热系统风扇所产生的噪音虽然不是很大却也和现在的环保观念相冲突,二来因为散热的需要,往往AGP插槽邻近的一两个PCI插槽都不能安装相应的设备,对于某些朋友来说这样也是种烦恼。

显卡需要输出
图9中的接口是显卡用来输出信号到不同设备,最左边的是标准D-Sub接口,这是用于连接我们最常用的显示器;中间的小圆口是视频输出端子,用于把信号输出到传统的电视机,也被那些支持视频输入的显卡用于接收模拟视频信号;最右侧的接口叫做DVI(Digital Visual Interface),中文名是数字输出接口,配合具有DVI接口的显示器使用(常见的如带DVI接口的液晶显示器),可以获得不失真的数字图像。DVI对于图形工作者来说是福音,也是未来的标准配置。

依靠多个输出接口,现在的显卡都可以实现多头功能,使你的系统桌面可以同时在两个甚至多个显示器上显示,大大方便使用。例如一个显示器用来上网,另一个用来同时播放DVD;编辑多个文档时也用不着在任务栏来回切换;处理图片时,一个看整体效果,一个处理局部细节,非常方便!
小知识
什么是DVI
虽然DVI接口已经在新显卡上遍地开花,但是很多朋友对它的理解仅限于“从来没有机会使用的白色接口”。其实DVI作为一个重要的接口标准是由数字显示工作组(DDWG)制定,Intel和Silicon Image都是它的成员。目前在主流市场,显卡与显示器之间是通过模拟信号传递的。我们将数字信号与模拟信号做一个对比,可以发现数字信号仅仅包含“0”和“1”两个状态,高电平就是“1”,低电平就是“0”,细微的电压变化并不会干扰信号从而保证信号的正确;再看模拟信号,如果遭受某种外界因素干扰,例如电压波动,信号就可能变成1.0xxx或者0.0xxx,这样细微的误差反馈到我们看到的画面就产生了些许失真。所以为了获得完美的画面,我们要尽量避免把数字信号转换为模拟信号后再转回数字信号的多次数模转换,造成信号损失。这也就是DVI接口和普通模拟接口相比所具备的优势。
何谓PCI Express
PCI Express是PC内部连接的新技术,预计在2004年开花结果,但是估计不会快速普及于市场。英特尔是新一代PCI Express标准的强力支持者。现行计算机中普遍采用PCI架构来作网卡、芯片、声卡之间的连接。而PCI Express将大幅克服目前PC内部的传输瓶颈。目前计算机中采用最快的PCI的速度只有133MB/s,而PCI Express一开始就已经达到2.5GB/s,并且PCI-SIG协会表示,PCI Express最终将可冲上40GB/s!PCI Express将会彻底改变桌上型计算机的内部架构。首先被换掉的就是PCI总线与AGP总线,前者负责连接处理器与外围设备,如打印机,声卡等;后者则是CPU与显示芯片之间的专职通道。未来的电脑又会改变模样了!
经常会遇到有朋友问我,玩游戏时,为什么别人的速度、画质都比我的强?他的显卡比我的好吗?那究竟是什么在决定着一块显卡的好与差呢?今天就让我们来看看:
表现显卡真正性能的两大综合指标
我们平时玩的3D游戏中的人物、车辆、武器、以至于整个游戏的地理环境都是由3D图形构成。我们知道,屏幕中的一个3D图形其实是由成千上万个三角形或多边形组合成框架模型,再在这些框架模型的表面贴上各种纹理(在多边形中填充色彩)形成。当一个屏幕上的3D图形运动时,要及时地显示出一些原来被遮的部分,抹去现在一些显示的部分,还要针对环境以及光线角度的不同,使用多种色彩填充多边形让人“感觉”物体因为运动而产生变化,从而最大程度地模拟真实世界,给人真实的感觉。人的眼睛具有“视觉暂留“特性,当一幅图像不停地被多幅连续的只有微小差别的图像代替时,给人的感觉就不是多幅图像的替换,而是形成了一个连续的动作。
所以,显卡的“填充率(Fill Rate)”(控制3D表面变化)和“三角形(多边形)生成速度”(控制3D建模)很大程度上决定了3D图形的品质。“填充率”以每秒钟填充的像素点为单位,“三角形(多边形)生成速度“则表示每秒钟三角形(多边形)生成个数。现在的3D显卡的性能也主要看这两项指标,这两项指标的数值越大,显卡3D图形的处理能力就越强,显卡的档次也就越高。
显卡的填充率
各大厂商在介绍和推广自己的产品时,总是把填充率作为一个重要指标来大肆宣扬。不过有些公司用pixels(像素填充率)而另一些却用texels(纹理填充率)来定义。
像素填充率
早期大多数公司在产品上标注的填充率实际指的是显卡的像素填充率。它代表着显卡芯片每秒能够渲染的最大像素量。那么那些填充率的数值是怎么得来的呢?要获得一块显卡的填充率的前提条件是必须知道显卡芯片的运行频率。将显示芯片运行频率和像素渲染管线的数目相乘,即可得到芯片的像素填充率数值。下面的几个例子有助于理解:
3dfx Banshee显卡芯片的运行频率为100MHz。它只有1条像素渲染管线,根据填充率的定义,Banshee的像素填充率就是100MHz×1=100 Mpixels/s(百万像素/秒)。
nVIDIA RIVA TNT有2条像素渲染管线,芯片运行频率为90MHz,很容易算出TNT的像素填充率为180 Mpixels/s。
nVIDIA GeForce FX 5800 Ultra显示芯片通常在500MHz下运行。它有8条像素渲染管线,每条管线一个纹理单元。根据填充率的定义,GeForce FX 5800 Ultra的像素填充率就是500MHz×8=4000 Mpixels/s。
ATi Radeon 9700 Pro显示芯片通常在325MHz下运行。它有8条像素渲染管线,每条管线一个纹理单元。根据填充率的定义,Radeon 9700 Pro的像素填充率就是325MHz×8=2600 Mpixels/s。
原来如此!不过事情可不是想的那么简单。上面的填充率都是在极端的条件下得到的。某些显示芯片却有限制,它们的像素渲染管线只能为同一个屏幕像素工作,如果像素为单纹理的话,那么第二个像素渲染管线就只好闲置了,这时填充率实际上很低。这里主要告诉大家的是:在不同的条件下,填充率可能有所不同。像素填充率是3D芯片运行频率与像素渲染管线数目的乘积,但这种填充率是在特定的工作环境下获得的,要求像素渲染管线可以同时工作。
让我们来体验一个复杂些的情况:试着计算一下nVIDIA GeForce Ti 4600的填充率,它有4条像素渲染管线,每条管线2个纹理单元,芯片时钟为300MHz,GeForce Ti 4600的像素填充率怎么计算?300MHz×4×2=2400 Mpixels/s?嗯,看来不错,可实际上呢?300MHz×4=1200 Mpixels/s,这才是正确的计算!那么300MHz×4×2=2400M是什么呢?答案就是:2400 Mtexels/s。这里,texels/s这个英文就是我们下面要讲的──纹理填充率。
纹理填充率
为什么有的厂商广告词中填充率的数字比计算出的像素填充率还要高?难道是厂商骗人吗?这里你所看到的填充率很可能就是纹理填充率而不是像素填充率!
纹理填充率是指一秒钟内纹理渲染的数目,计算公式同理论像素率相似:显卡芯片运行频率×像素渲染管线数目×每条渲染管线的纹理贴图单元数目。
哇,太难受了!不要紧,我们还是举例子:
GeForce4 MX440的芯片运行频率为270MHz,具有2条渲染管线,每条渲染管线具有2个纹理贴图单元,因此GeForce4 MX440的纹理填充率为270MHz×2×2=1080 Mtexels/s或1.1 Gtexels/s。
所以当你看到一个近似天文数字或比同一代其他显卡高得多的填充率时,你应当意识到那很可能是纹理填充率而不是像素填充率。纹理填充率从来都是以Mtexels/s表示,而不用Mpixels/s。
真实的填充率
我们知道,理论和现实之间总是存在巨大的差距,那么还是让我们回到真实世界中来吧。
怎样得到真实的填充率呢?很简单,测试!我这里介绍用3D Mark03来测试3D卡填充率(图10)。
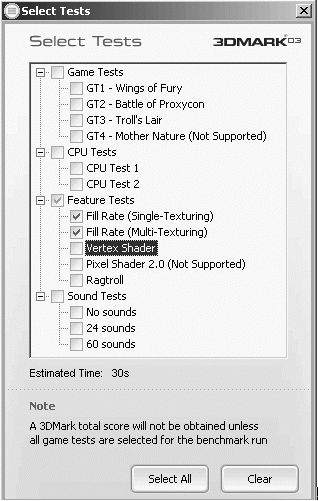
如果你用过3D Mark03,你应该见过图11这个场景。没错,这就是填充率测试。

过去定义填充率就是一秒钟内写入帧缓存的已渲染完毕的像素的数目。假设屏幕分辨率是800×600,那么每个平面都包含有800×600即480000个像素。将这个值与帧速率相乘(每秒画面显示的帧数),就可以得出填充率数值。
通过这个场景测试,可以反映显卡真实的填充率,我们看看真实的填充率和理论的填充率之间的差距,我们的测试平台为P4 3.06GHz,MSI GNB Max主板:
下表这些数据都证明真实填充率确实比理论填充率要小,没有一个显卡的填充率效率能达到理论值的100%,这很正常。我们可以用填充率的效率表示实际值与理论值的偏差。一般来说越是新的显卡核心,其执行效率就越高。我们在这里可以注意到,GeForce4 Ti的填充率效率比GeForce 3要出色得多。这里我们特别要提到ATi Radeon 9700 Pro的杰出表现,8条渲染流水线使它在单纹理填充率的测试中一马当先。
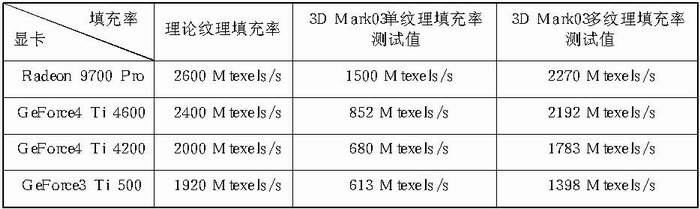
以上数据还揭示了显卡芯片运行频率和填充率之间的关系:显卡芯片运行频率越高,填充率越高。
关于填充率的总结
填充率是3D厂商争夺用户的主要武器,每个公司都会以惊人的数字来吸引用户。遗憾的是,填充率有很多种定义,容易使人们误解。我总结了两种类型的填充率:像素填充率、纹理填充率。但是所有这些都是理论上的数据,缺乏实际意义。
为了搞清楚真正有效的填充率,我们需要了解真实填充率的情况,3D Mark可能不是最好的,但是它的测试结果比那些理论的数据可靠得多!理论不等于实际──厂商极力吹嘘,只不过是想让你认为他们的产品是最好的。
小知识:
像素:计算机图形中的基本单位。我们在计算机屏幕上看到的图片其实是由一个一个的像素点组成的。例如分辨率为1024×768的一帧图像是由786432个像素组成。显卡控制每一个像素点的色彩变化从而控制整个图形的色彩变化。
纹理:纹理本身是种2D图形,通过纹理贴图技术将2D图片映射到3D图形上,用来表现3D图形的表面特征。因为在现实世界中,任何物体的表面都有自己的特征,如一堵水泥墙,表面灰色、粗糙就是它的特征。通过纹理贴图,3D图形会更有真实感。 渲染:由于显示器显示的内容在不断地变化(如3D游戏场景的变化),显卡需要不断重新计算每一个像素点的颜色和亮度的变化,从而控制图像显示。这个处理过程就被称之为渲染。
像素渲染管线:就是显卡完成每次渲染的必经工作流水线。它的工作原理如何?可能许多朋友并不明白,但这没关系,只要记住以下几点,你对像素渲染管线的重要性就一清二楚了。
1.对于一个显卡来说,填充率是硬指标,填充率越高,显卡越好;
2.像素填充率=显卡芯片运行频率×像素渲染管线数;
3.扩充渲染管线是提升显卡性能的法宝;
4.所以阉割渲染管线也就成了抑制显卡性能的法宝。典型的例子就是最新的Radeon 9500PRO和Radeon9500,这二者的128MB版本有同样的核心速度和显存速度,但是前者效能远胜后者,就是因为9500被人为地关闭了一半的渲染管线使得图形处理能力大大下降。
这里,我们将谈论另一大指标──多边形生成率。显卡厂商一般都会用醒目的字体把多边形生成率标示在包装盒上向人展示。那么这个多边形生成率到底是什么呢?它到底有多重要?让我们一步一步来看。
多边形是构成3D世界的基础
我们平时在计算机屏幕上所看到的一切3D图形,包括人物、车辆、武器、也都是由无数个多边形构成的。为什么这样说呢?因为电脑在进行3D图形处理时,一般是将屏幕中的一个3D物体分割为成千上万个三角形。我们先来看一幅3D图形,就会了解电脑的显示系统是如何构成3D图形的了。
图12是ATi用来展示显卡性能的3D虚拟女性Rachel,她的一颦一笑,都栩栩如生。那么计算机是如何生成这样的形象的呢?我们现在看到的是完整的带有纹理的最终生成画面,那么让我们剔除外面的纹理,来看看这位美女的本质:

瞧瞧,通过图13你看到了什么?对,大量的三角形构成了Rachel的一切。这些三角形就是3D图形的骨架。仔细观察上面的截图,我们可以注意到Rachel的额头、眼角、嘴巴是三角形使用最密集的地方,因为人类脸部的这些地方运动最频繁,而为了能够忠实地再现人类脸部的运动,大量使用多边形构建模型的骨骼是必需的。有过3D图形制作经验的读者都知道:在制作3D图形的时候,建模的好坏直接影响着最终成像。从理论上讲,一个3D模型使用的三角形数量越多,它经过渲染后的成像效果就越好。让我们先来看一幅显卡渲染同一个物体的对比图,看看多边形数量的多少会对最终的成像效果带来什么样的差异。

图14是ATi在展示Truform技术时用的两只3D海豚模型,通过仔细比较图中的两只海豚,我们可以看到下方的那一只比上方那只的动作更柔和,整体的光影和曲线也更加真实。我们再来看看这两只海豚的3D模型骨架(图15),比较一下它们使用的多边形的差异。


怎么样,图14中那只棱角分明的海豚是用少量的三角形构架的。而它下面那只圆滑而灵活的海豚,所采用的三角形比起上面那只海豚要多出不少,这才有了我们看到的圆滑而自然的最终显示效果。
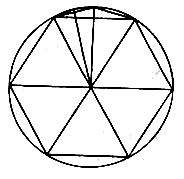
那么为什么优秀的3D图形画面必须采用大量的三角形呢?这是因为真实世界的物体的构成十分复杂,看似简单的一个物体都拥有大量的不规则多边形。但是对于电脑图形来说,是不能使用不规则的多边形来构图的,因为这样的话,3D建模所需要的顶点运算就是一个无比庞大的计算量,这无论对于现在的CPU、图形处理器还是显存和显示总线的带宽来说都是难以承载的。幸好我们的祖先在计算圆周率的时候,就已经发现了用三角形来分割圆形,三角形用得越多,就可以无限地接近一个圆,这就是魏晋时期数学家刘徽所创立的方法──“割圆术”。
按照这个方法(如图16所示),越是把圆周分割得越细,误差就越小,其内接正多边形的周长就越是接近圆周。如此不断地分割下去,一直到圆周无法再分割为止。也就是到了圆内接正多边形的边数无限多的时候,它的周长就与圆周“合体”而几乎一致了。如今,这也成了计算机3D构图的理论基础。我们在构建3D物体的时候,并不采用各种各样的真实世界的图形形状,只是用多边形(三角形)来构筑任何现实中的图形,所以构建一个模型时使用的三角形数量越多,模型的表面曲线就越平滑,模型的效果就越接近原物体。
在现在的游戏中,一般构建人物模型时使用了1500~6000个三角形,更有甚者使用2万个以上的三角形来构建。我们可以粗浅地计算一下,在保证流畅的最低标准(每秒显示60帧)的情况下,单单一个游戏人物的显示运算就要求显卡起码达到每秒120万个三角形的生成速率,更何况加上其他的人物和背景。现在大家知道为什么多边形(三角形)生成率是每个显卡厂商都重点标榜的数值了吧。
理论多边形生成率
厂商推出的最新显卡不断地刷新着多边形生成率的记录,通过表一我们可以看到目前主流显卡的多边形生成率。
从这个规格表中我们可以看到:新的一代王者显卡(例如NVIDIA的GeforceFX或者ATi的镭9700PRO)的多边形生成率都已经达到了每秒3亿个以上。这相对于GeForce 4 Ti4600的1.3亿的生成率来说有了显著的提高。
不过,设计厂商提供的这些多边形生成率,我们称之为理论多边形生成率。拿 GeForce FX来说吧,如果我们吹毛求疵一点的话,那么它标称3.5亿的多边形生成率是有苛刻的生成条件的,即这些要生成的三角形必须以条形或者扇形的方式彼此相连在一起,这样在进行3D运算的时候,每生成一个新的三角形,GeForce FX其实只需绘出新三角形的一个顶点即可。我们也知道,在实际的游戏中,这样的理想状态是根本不存在的。一般来说游戏设计者要让生成的三角形彼此独立存在,那么GeForce FX就必须绘出这个三角形的三个顶点,这样一来,其三角形生成速度每秒只有1.1亿多个了,也就是只能达到理论峰值的三分之一左右。并且这个三分之一也是不介入光源计算、纹理贴图后的理论值,如果再加上这些,多边形生成率还要大打折扣,甚至衰减到理论生成率的十分之一都不到。
真实多边形生成率
既然我们已经了解了多边形生成率的理论值和实际应用之间存在着巨大的差距,那么有没有一个基准测试可以帮助我们了解显卡在实际工作中的多边形生成率呢?答案就是3D Mark2001SE。不知道为什么,最新的3D Mark03中没有了多边形生成速率的测试,我们只好继续沿用过去的3D Mark2001SE的这项测试。在没有新版本之前,3D Mark2001SE的High Polygon Count(多边形演算)子项目(图17)就是目前测试实际多边形生成率较好的测试软件。

在这个测试中,采用了一个近似于游乐场中的旋转木马的3D模型来测试显卡生成多边形的速度,主要是用来考验显卡的多边形生成能力。测试当中使用的旋转平台模型是由大量多边形构成的物体,据官方的说法,这样一个测试场景每帧由超过100万个的三角形构成。并且这些多边形会随着光照的变化而产生变化,这对显卡的多边形生成率是个考验!High Polygon Count是由两个子测试项目组成的,其中的每一个测试程序都设置了不同的光源,分别为High Poly 1 Light Test(仅仅加入一个单向光源的测试)、High Poly 8 Light Test(1个单向光源加上7个点光源的测试)。为了精确得到多边形生成率,这个场景采用了很简单的纹理贴图。
看看我们选测的一些主流显卡的结果(表二),了解一下它们的真实多边形生成率。测试平台为AthlonXP2400+和微星的KT3V主板。
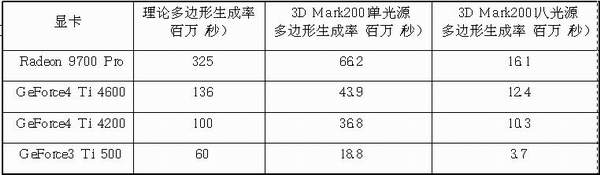
表二中多边形生成率测试的赢家还是ATi的R300核心,但是从理论多边形生成率和实际多边形生成率的比率来看,NVIDIA的GeForce 4 Ti系列的多边形生成效率是非常优秀的。
关于多边形生成率的总结
显卡厂商总是标示很高的多边形生成率,但是我们通过实际测试,发现这种理论值和实际应用的差距是巨大的。特别是在3D Mark2001的测试中我们可以看到,加入了多点动态光源后,对于显卡的多边形生成能力是一个巨大的考验。这也从侧面显示了为什么像《DOOM3》这样的新游戏可以成为“显卡杀手”,因为高精度人物建模和大量的实时光源处理对于现有显卡的多边形生成能力是一个巨大的考验,这还不包括它采用的高精度纹理对于显卡渲染能力的吞噬。虽然游戏的画面越来越漂亮,我们依旧可以说如要展现真实的世界,我们的现有显卡的硬件运算能力还远远不够!
小知识
ATi的Truform技术
ATi的Truform 技术是ATi 从Radeon 200图形芯片开始使用的3D显示技术。其主要目的是改变3D的显示效果,即自动在3D模型表面增加多边形,以使3D表面看上去更加平滑,更接近真实的物体。而这过程均在显卡芯片内部计算处理完成。不过有一点需要注意,Truform技术除了需要硬件及驱动程序的支持之外,游戏软件也必须支持 Truform技术。
我们在前面向大家介绍了表现显卡性能的两大指标──填充率和多边形生成率。那么还有那些因素可以影响显卡的性能表现呢?下面就让我们来看看。
一、显卡系统的“咽喉”──显存带宽
显存带宽就是指图形处理器与显存间数据传输的速率,以字节/秒为单位。显存带宽与系统内存带宽的原理、作用很类似。众所周知,GPU核心频率提升带来的最直接好处就是像素填充率也跟着提高。像素填充率越高特别是在显示分辨率高的时候,GPU所需要处理的像素和纹理就越多。如果显存带宽满足不了数据传输的需要,就会影响显卡整体性能的发挥。这好比同是一颗P4的“芯”,但因双通道DDR系统拥有更高的内存带宽而比单通道DDR系统有更好的性能。因此,显存带宽是除GPU自身性能之外,另一个决定显卡性能和速度的重要因素。
要得到高分辨率下色彩逼真和流畅的3D画面,就必须有更高的显存带宽。根据带宽的计算公式(显存带宽=工作频率×显存位宽/8),我们要提高显存带宽可以从提高显存工作频率与显存位宽这两方面考虑,而这也是当今高性能显卡发展所面临两个选择。目前ATI主要在DDR显存的基础上往更高的显存位宽(256bit)发展;而NVIDIA的最新一代NV30显卡则通过采用更高频率的DDRⅡ显存来提高显存带宽。不过,就目前生产技术来说,通过提升显存位宽比提升工作频率要相对容易得多,而带来的性能优势更明显。
但通过以上公式得出来的显存带宽只是一个理论值,而显卡在运行中所获得实际显存带宽却要低于其理论值,因此,各大显示芯片厂商都针对自己产品的特点研发了一些优化显存带宽的技术。比如ATI的Hyper-Z技术(可以提高Radeon系列20%~40%的执行效能),NVIDIA的交错式显存控制器技术、在最新一代NV3X上采用的色彩压缩引擎技术等等(以NV31为例,其显存理论上最大只能提供11.2GB/s的显存带宽,但是通过色彩压缩引擎的4∶1压缩后就可以获得最大44.8GB/s的显存带宽)。
不过,过高显存带宽值也并不意味着可以给显卡带来更高的性能。因为显卡GPU的像素填充率达到它的设计最高值时,它就只能工作在某个分辨率上,此时如果过分提高显存带宽值的话,就意味着没有足够的数据来充分利用它,面临“有路无车”的尴尬局面。
二、显卡的“秘密”通道──AGP
就整个系统来说,显卡就好比一个相对独立的加工厂,如果要把显卡所有“加工处理的产品”传输到系统里,就必须建立一条传输通道。而目前显卡的“秘密”通道主要是AGP。
AGP目前已经发展到第四代──AGP 8×。其最大理论传输带宽达到了2.1GB/s,是AGP 4×的两倍。除了频宽加倍之外,AGP 8×在规格上也有诸多提升之处,像支持超大影像对映区、超大虚拟寻址能力等等。不过大多数朋友主要关心的是AGP 8×在游戏方面能有什么作为,所以我们在这方面简单阐述一下。
谈到AGP 8×能对游戏用户带来什么,首先得从Vertex Shader(顶点着色引擎)谈起。目前基于DirectX 8的游戏程序有一个重要的特点,那就是应用Vertex Shader(使用针对几何顶点的图形程序。顶点就是角点,是构成多边形的最基本图元,Vertex Shader就是描述这些顶点位置的程序)。Vertex Shader可以由GPU或者CPU来执行,如果使用GPU来执行的话,Vertex Buffer(顶点缓存,存放场景顶点数据的地方)多数会放在显卡本地显存里,大多数可以由硬件执行Vertex Shader的GPU(例如NV2X、NV3X、R200、RV250、R300等)都具备64MB甚至更高容量的本地显存来存放顶点数据。此时AGP 8×相对于AGP 4×来说,只是在传递渲染指令上有优势。但是目前的游戏对于渲染指令的传输并不需要很高的带宽(这主要是由于目前游戏普遍并没有应用到十分大的纹理素材,比如1600×1200分辨率或者立体式的Cube纹理),因此对于具备硬件Vertex Shader的GPU来说,AGP 8×目前没有什么特别的优势可言。真正让AGP 8×发挥作用的是类似GeForce4 MX440这类需要CPU来执行Vertex Shader的显卡。由于CPU需要经常性访问Vertex Buffer,Vertex Buffer最好放在AGP显存中,CPU透过AGP总线访问这块Vertex Buffer,此时AGP 8×的优势就会比AGP 4×明显的多。
三、显卡世界中的“美容术”──反锯齿技术
由于计算机3D图形有自身的构成特点(我们在上期文章中讲述过),因此显示出来图像的边缘总是呈锯齿状。对追求视角完美的用户来说,这是一个致命的缺点。为解决或缓解这个问题,各大绘图芯片厂商研发出了针对自身产品的反锯齿技术,让3D图形边缘出现的锯齿变得更为圆滑(如图18所示)。

在反锯齿处理方面,NVIDIA在GeForce3时在原Supersampling(超级采样)的基础之上提出多重采样的观念。这种反锯齿的方法好处在于:只需要渲染待反锯齿的场景一次就可以达到效果,从而降低了对GPU计算资源和显存带宽的消耗。但是在实际使用中,这种技术的效果并非这么优秀。而到了GeForce4时代,NVIDIA又提出Accuview Antialiasing(锯齿失真修正,即FSAA)技术,这是一种高解析度反锯齿多样本技术,提供了2×与4×的Quincunx及新的4×S模式(其中4×S对于处理较长斜线的反锯齿有着更好的处理效果,不过只在Direct3D上才能表现其效果。)。在步入GeForce FX时代后,NVIDIA在NV30中又引入了智能型防锯齿功能(融合在Intellisample技术中),可捕捉较高分辨率的影像,然后调整影像大小并重新取样,最后再输出至屏幕,从而彻底消除了各种瑕疵。其中新增的6×S模式比目前的4×或4×S模式多计算50%的取样,从使游戏画面表现出更高的清晰度。
显卡界另一巨头ATI主要以SmoothVison抗锯齿技术为主,相当于NVIDIA的全屏幕抗锯齿(FSAA)技术。在Radeon 9700以前(如ATi Radeon 8500),ATi的SmoothVison反锯齿是一种超级采样算法,并没有采用类似NVIDIA的多重采样技术。超级采样技术通过渲染出场景的多重拷贝,把它们进行位移叠加而得到最终的反锯齿效果,这种方法在提供优秀的纹理分辨率的同时也除去了锯齿,当然它需要显卡芯片拥有极高的填充率,因为需要对一幅反锯齿的场景需要进行多次渲染。由于SmoothVision强调的是画质,占用的系统资源和显存带宽比较多(这就是为什么ATI显卡比NVIDIA显卡对CPU的依赖程度要高的原因之一),鉴于多重取样反锯齿技术具有降低对GPU计算资源和显存带宽的消耗的优点,所以ATI在R300芯片中对超级采样反锯齿和多重采样反锯齿都加以支持。ATI把R9700芯片上应用的多重采样反锯齿技术命名为“SmoothVison 2.0”,支持2×、4×和6×AA反锯齿模式。
目前,各绘图芯片厂商都在驱动程序中增设了相关反锯齿设置功能,我们只要在显卡的控制台程序中选择手动方式,就可以启动不同的反锯齿处理效果。
就目前的抗锯齿技术来说,除了进一步的提高采样数量之外没有更好的方法来解决这个问题。当然这样就会使得显卡的性能有了明显的下降,尽管目前所有的厂商都宣称自己的图形芯片都可以在不损失或者很少损失性能的情况下得到更好的抗锯齿效果。因此在你还没有拥有一款性能强劲的显卡之前,最好适度地使用抗锯齿功能。另外通过提高分辨率可以降低锯齿对视觉的影响程度。
四、显卡特效与DirectX 8/9
自从微软件在DirectX7中引入对T&L(坐标转换和光源)的支持后,显卡芯片就开始往GPU方向发展了,从此特效也与DirectX挂上了钩。至此,显卡技术的发展已不再仅仅局限于频率、带宽、晶体管数量的提高,而越来越多的新特性被加入进来。很长一段时间里,3D游戏制作者一直期待能在实时运算中获得与现代电影相似的前沿特效技术。这让微软在2000年推出的DirectX 8中首次增加了“可编程”特性:一个可编程的Vertex Shader(顶点着色引擎)代替了过去的T&L引擎;而可编程的Pixel Shader(像素着色引擎)则加入了过去的纹理处理流水线。这是一个划时代的改进,通过Vertex Shader和Pixel Shader的渲染,3D游戏制作者可以很容易的营造出真实的水面动态波纹光影效果(如图19)。而是否支持DirectX 8也成为了划分显卡等级的界线。

今年发布的DirectX 9与DirectX 8相比又是一大飞跃。DirectX 9中的Vertex Shader2.0标准增加了流程控制,更多的常量,每个程序的Vertex Shader指令增加到了1024条。利用2.0版本的Vertex Shader,开发者只要写一个通用的光影处理着色引擎,通过调用不同的子程序就能处理任意数量、任意色彩、任意角度、任意位置的光线照射效果。尽管新的Pixel Shader2.0标准不支持流程控制,但最大指令数增加到了160条,增加高级效果所必需的算术运算指令,更重要的是指令的执行方式发生了本质变化:支持Pixel Shader2.0的绘图芯片将再也不是只能执行一些极其简单的纹理取址指令和颜色混合指令的简单逻辑阶段开关了,而是成为了真正意义上的处理单元,很大程度上解决了复杂像素着色程序带来的像素填充率降低的问题。然而,DirectX 9真正关键的特性是64位色彩(RGB三色,每种颜色信道16位+16位Alpha透明通道)和128位浮点精度(每种颜色信道32位浮点)。颜色精度的巨大增加将带来更高的图像质量和更逼真的视觉效果(如图20所示)。

今年各款新版本的游戏都将基于DirectX 9.0开发,但由于DirectX 9是基于DirectX 8的架构,都是以co-CPU(cooperative CPU,协处理器)的方向发展,所以就算GPU没支持到的硬件加速函数部分,还是可以通过CPU和仿真加速器来模拟、仿真,只是效果与速度一定没有通过硬件的加速好、快。因此,即使你的显卡不支持DirectX 9.0也可以运行DirectX 9.0的游戏,当然你也不能很好欣赏到在支持DirectX 9.0的3D游戏中,像电影般的高质量画面。不过我认为目前选择一款显卡的最低标准是支持DirectX 8.0,这样可以较好地减少在DirectX 9.0游戏中的失真现象。