“扫”进美丽──轻松学用扫描仪
专题快递
编者按:
如今家用型中低档扫描仪的价格消费者普遍能接受了,因此扫描仪普及得很快。通过它我们可以把图片、照片扫描到电脑里,做一本自己的图片收藏集,或是通过E-mail发给朋友;还可以配合“文字识别软件(OCR)”把文字资料扫描进电脑,并把它迅速转换成文本文档,省去了大量输入的烦恼……你看扫描仪的作用是不是很大,既能增添我们生活的情趣,又可以提高我们的工作效率。
一、扫描仪的安装与检测
扫描仪同电脑的连接跟F1版介绍的打印机是相同的,但假如并口已被打印机占用了,又想同时使用扫描仪怎么办呢?别急,扫描仪背面还有一个标有“Printer”的接口,只须将打印机数据电缆的一端接上即可。
安装好扫描仪,启动Windows XP后即会检测到新设备。驱动程序的安装方法跟F1版介绍的打印机基本相同,这里不再重复了。
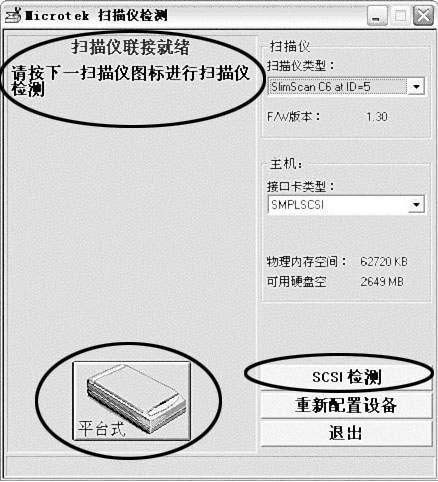
为了确认扫描仪工作是否正常,要对它进行扫描检测:打开“控制面板”,单击“打印机和其他硬件”选项,再选“扫描仪和照相机”。在左侧的“图像处理任务”中单击“扫描仪检测”,打开“Microtek扫描仪检测”对话框,如(图1)所示。窗口左侧中显示“扫描仪联接就绪”字样,单击“平台式”按钮,弹出“扫描仪检测”的确认对话框,单击“确定”按钮,开始检测扫描仪并进行扫描。如果一切正常,单击“确定”按钮完成扫描仪检测。
二、一般图片扫描
扫描图片需要扫描仪和图像处理软件互相配合使用。除了购买扫描仪时,厂商附赠的用于扫描图片的图像处理软件外,我们通常使用Photoshop来进行图片扫描工作。下面就以Microtek扫描仪为例,介绍如何利用扫描仪和Photoshop来扫描图片。
1.在完成了扫描仪的测试工作之后,就可以正式开始扫描图像了。把要扫描的图片放在扫描仪中,注意图片正面向下,并盖好扫描仪上盖。
2.启动Photoshop,打开它的工作窗口。单击“文件→输入→Microtek ScanWizard(32 Bit)”命令,启动扫描仪向导。随着打开“预览设置”窗口,如(图2)所示。
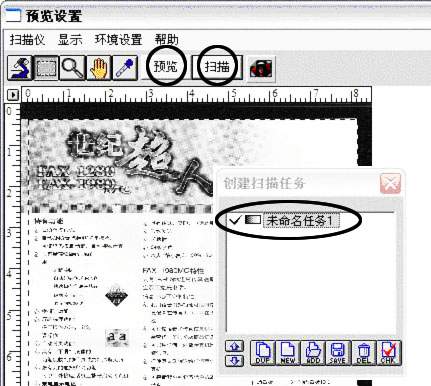
3.单击“显示→显示扫描设置窗口”命令,打开“未命名任务1”对话框,如(图3)所示。在此对话框中可以设置扫描属性,诸如分辨率、扫描比例等。
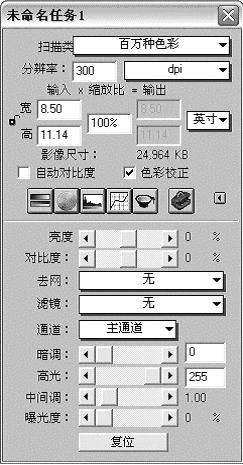
4.扫描的属性设置好后,单击“预览设置”窗口中的“预览”按钮,开始快速预扫描,预扫后我们还可对扫描参数进行设置。然后单击“扫描”按钮即可进行最终的扫描。扫描完成后,自动把扫描所得的图片传送到Photoshop中,并在程序窗口中显示出来,我们就可以对图像进行处理。
图片的扫描在《电脑报》2002年第19期F版块专题版《让图片处理平民化》专题中有比较详细的介绍。
我们下面就来介绍扫描仪和“汉字识别”软件是如何携手工作的。
三、“文字识别”扫描
有了扫描仪,我们收藏资料会方便很多。特别是文字资料,我们可通过“汉字识别”(OCR)软件将扫描图像中的文字转换为计算机能编辑的文本文件。例如我们想把一篇论文扫描进计算机,首先是把这篇论文经扫描仪扫描为图像文件,然后通过OCR软件去识别上面的文字,并且将修改识别后的文字保存为可编辑的TXT文件。同时,OCR软件还具有简体多体 (宋体、仿宋体、黑体、楷体、魏碑)、繁体多体、中英文混排、横竖版面混排识别及版面分析等功能。下面我们以《尚书汉字识别系统》为例介绍如何使用OCR软件(购买扫描仪时厂商一般会配送一套OCR软件,可能跟本文介绍的软件不同,但使用方法是差不多的)。
1.扫描稿件
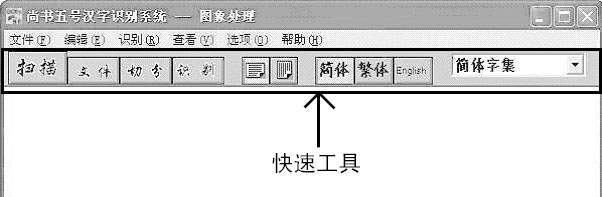
1)先启动《尚书汉字识别系统》,打开它的工作窗口,如(图4)所示。将扫描稿件(最好使用清晰的打印或印刷稿件)文字朝下摆放端正,盖好扫描仪上盖,单击工具栏上的“扫描”按钮,打开“预览设置”对话框。扫描参数中分辨率可设为300 dpi,如果原稿字号过小时应设为600 dpi,色彩模式设为黑白模式(OCR只能识别黑白图像上的文字)。
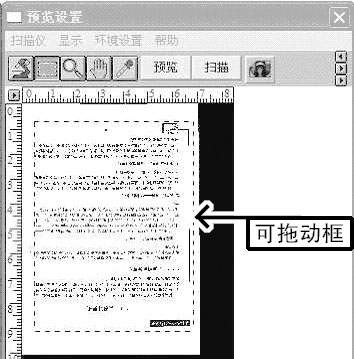
2)设置完成后单击“预览”按钮,扫描仪开始启动预览扫描。稿件样张呈现在“预览设置”对话框的窗口中,如(图5)所示。拖动虚线框,使它能包含需要《尚书汉字识别系统》转换的文字。注意,虚线要和文字分开一段距离。然后单击“扫描”按钮,正式开始扫描。
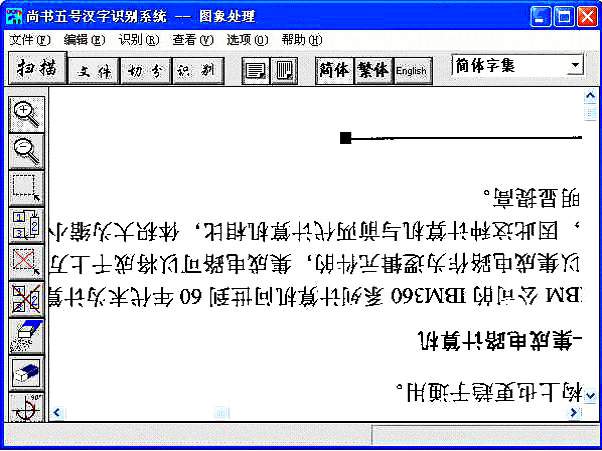
3)扫描完成后,退出扫描界面,图像自动生成在“图像处理窗口”中,如(图6)所示。但是在识别界面中看到的稿件内容仍然是不可编辑的图像文件,在文字识别之前需要对图像进行版面处理,如版面的倾斜校正。还要按稿件格式划分几个识别的区域并分别设置各个区域的属性:是横排还是竖排,是简体还是繁体等。
4)上面扫描完的图像是上下颠倒的。修改的方法是单击左侧工具栏中的“旋转图像”按钮,可以把这个图像旋转90°、180°或270°。
5)单击左侧工具栏中的“创建识别区域”按钮,对需要用OCR转换的文字处理时,按鼠标左键拖出一个矩形,使它能包含全部文字。确认所有要识别的文字都在划分的区域内,对于区域以外的文字可以拖动区域框来改变区域大小。创建好识别区域后,单击“横排”、“竖排”按钮可以调整识别后文本的排版效果。
6)单击工具按钮栏中的“简体”、“繁体”以及“English“按钮,可以把扫描结果调整为简体、繁体或是英文。
2.文字识别
把版面调整到满意的效果后,就可以开始识别了。单击工具栏上的“识别”按钮,《尚书汉字识别系统》软件开始进行文字识别。完成后,自动进入“文稿校对”窗口。在这个校对窗口中,我们就可以对文本做修改和编辑了。移动光标,窗口下部的图像会随着光标的移动而显示相应的文字。如果识别后有些文字和图像中的文字不一样,可以进行修改和编辑。具体方法是:
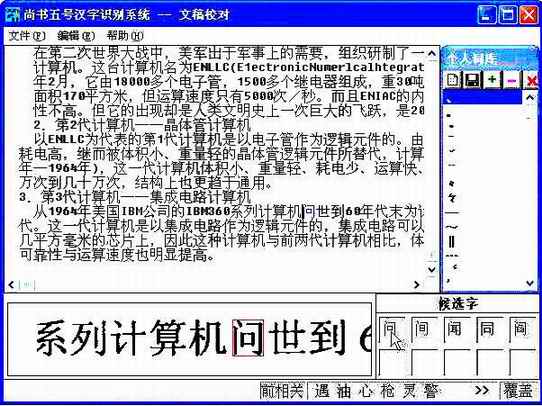
1)如(图7),移动光标定位到需要修改的文字前,在“候选字”窗口中出现可以用来更正的文字。单击正确的汉字,即可将这个正确字符插入到错误的汉字前,并将错误的汉字删除。
2)如果《尚书汉字识别系统》不能够确认该汉字是否被正确识别,会用绿色来显示该汉字字符。
3)把稿件内容校对编辑后,就可以保存了。也可以在识别完成后,把稿件保存为TXT文本文件,再使用其他的文字编辑软件(如Word、WPS等)来编辑排版。
4)最后要退出《尚书汉字识别系统》,先选择“文件→结束文本校对”命令,关闭《尚书汉字识别系统》的“文字校对”窗口;然后在《尚书汉字识别系统》的识别界面中,选择“文件→退出”命令,弹出一个对话框,确认是否保存修改过的图像文件,单击“Yes”按钮,保存该文件。最后程序自动退出OCR程序,一个完整的扫描识别过程就结束了。
3. 注意事项
1)如果需要识别繁体中文、韩文或者日文,需要相应的数据文件支持。
2)报纸的扫描识别,请在报纸上加压一些书本用来消除报纸与玻璃板之间的缝隙;对于较厚的书本,则要将扫描仪盖板取下,用别的物品或手工压住要扫描的书本。
3)目前的OCR软件对表格的识别不尽如人意,尚书六号对表格识别相对较好。
4)原稿放置在扫描仪玻璃板上时,尽量不要歪斜。
5)不同的软件,具体操作会有一些区别,但原理和步骤基本是一致的。