AMD,64位再现雄风(上)
硬件周刊
早在4年前就有分析家指出,x86体系已经走到了其性能极限。然而事实正相反,Intel再次把脱胎于x86 ISA结构的P6 CPU推上了市场主流的位置,而AMD更是将K7架构发展延续下来。对于即将到来的64位计算而言,又一次将问题归结x86体系是否立即淘汰,还是进一步改进。这次,AMD与Intel走了两条截然相反的道路。
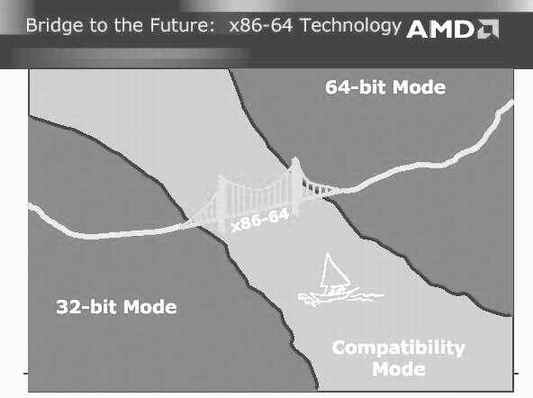
Intel投向全新的IA-64。目前基于32位的应用程序铺天盖地,这样最新的64位处理器必然不能在传统的应用程序中表现出全部的性能,这点就像当初的Pentium Pro一样。而AMD选择的道路似乎更加符合用户的应用需要,那就是将x86进行到底。当然,AMD也不会简单地因循守旧,而是将x86进行彻底的改进。CPU向64位发展是必然的趋势,但是传统的x86架构并没有错,只要对它进行升级,这样就能即保证其兼容性又能大幅提高期性能,这就是AMD所倡导的x86-64架构体系((图1))。
延续x86的神话──x86-64架构
由于Hammer保留了x86,因此其兼容性应该说是完备的,这点用户可以完全放心,因为其核心对32位和64位应用程序能够很好地支持。从应用角度来看,AMD的方案中从32位到64位的移植可谓无缝链接。不用说是现在的32位程序,即使是早先的16位程序也可以在Hammer上稳定高效地运行。
完备的兼容性主要来自于Hammer为不同的程序代码类型设计了不同的工作模式,它们分别是传统模式(32-bit Mode)、兼容模式(x86-64 Compatibility Mode)和64位模式(64-bit Mode)。兼容模式允许系统与现有的16位和32位的应用程序兼容,在64位操作系统下这些应用程序可直接编译。它和64位模式相同之处在于操作系统都是为满足个别代码区段的需要而建立起来的,与64位模式不同之处在于它采用的是16位或32位的保护模式。从应用程序的角度来看,兼容模式沿用了旧的x86保护模式。从操作系统的角度来看,内存寻址、中断和逆项操作以及系统数据结构均采用了64位的长模式。
另外很值得一提的是传统模式(Legacy Mode),相对兼容模式而言,它对32位程序的执行效果更好,因为在这种模式下,CPU根本不考虑任何64位指令,这样可以节约很多资源。此外这种模式也支持存储器分段、32位通用寄存器和指令指针寄存器分段等。
需要明确指出的是,64位指的不仅仅是64位程序代码,还包括内存寻址范围。其实Intel早期的80386处理器就开始支持32位代码,而直到Pentium Pro,32位寻址才被正式支持,可见CPU的内存寻址范围是多么重要!传统的32位CPU因为内存寻址能力方面的缺陷而导致其在大型数据库、互联网ERP和新型LOB(Line of Business)等应用程序中不能充分发挥性能,毕竟来说对于这类应用程序而言内存容量是多多益善的。而在AMD的x86-64中,内存寻址能力将史无前例地提高到4.5TB,如此大的内存已能充分满足当前和将来的软件应用需求。
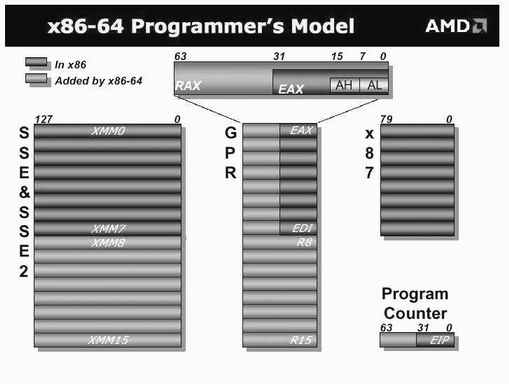
x86-64架构对CPU浮点性能的贡献也是巨大的,Hammer也将得益于此而继续保持AMD在这方面的领先优势。在传统x86处理器中,80位的寄存器构成了一个严重妨碍性能发挥的“堆栈”。举例来说,凡打算为一个算术表达式赋值的代码序列都需要通过额外的指令才能和运算对象“正面接触”,“罪魁祸首”正是以堆栈为基础的计算模型!通过数据流分析,若判定一些值以后还要在程序中用到,那么x86堆栈模型也需要额外的指令来保存这些中间值。而在AMD的x86-64架构中,这个问题得到了完全解决。整个编程模型更改为“浮点寄存器档案”,也就是说一条浮点指令需要从两个寄存器中取得它的运算对象,然后将结果回写至第三个寄存器((图2))。
全新的设计理念──Hammer内核剖析
如果想在性能取得更大的突破的话,那么CPU必须在设计理念上有所改进。AMD的Hammer处理器将带给我们全新的概念!
未来AMD Hammer处理器的正式名称将为Opteron与Athlon 64,其中Opteron面向服务器市场,也就是以前SledgeHammer,而第八代AMD Athlon 将主攻主流桌面市场,也就是以前的ClawHammer。
AMD新一代Hammer系列处理器的内核架构是由DDR内存控制单元、Opteron(或第八代Athlon)处理器内核、一级指令缓存单元、一级数据缓存单元、二级缓存单元和HyperTransport总线控制单元,这6个部分组成。除了x86-64的架构体系,Opteron将带给我们的最大惊喜莫过于整合的DDR内存控制单元与HyperTransport总线。
在传统的CPU架构中,内存控制单元都是整合在北桥芯片中,因此在传输数据时不得不经过一定的等待周期。但是,一旦内存控制器被装载到CPU内部,那么其速度将发生翻天覆地的变化。整合内存控制器的好处在于CPU可以直接和内存交换数据,而不需要通过系统总线传给芯片组,然后再传输给内存,这就大大缩短了数据交换时间,提高了性能。据保守估计,仅仅是这一项改进就能给CPU带来至少20%的性能提升!
(注:图片资料由AMD公司提供)