GeForce4:攀登3D之巅
硬件周刊
当NVIDIA周期性更新产品的步伐成为3D行业的脉搏时,当我们已经习惯于期待这半年一度的疯狂时,当竞争者们也开始参与这“N字打头”的节日时,你就会明白:为什么春天比秋天更激动人心──因为在3D世界秋天仅仅是“改善和升级”的日子,而春天才是“改朝换代”的开端!
去年春天我们迎来了划时代的GeForce3──它带我们进入了连专业3D都未曾涉足的领域,还没等我们享受到GeForce3的真实力量,NVIDIA又在半年后推出了一系列以Ti命名的新产品:GeForce2 Ti、GeForce3 Ti200和GeForce3 Ti500。现在,当NVIDIA换代的车轮滚滚而来,2月7日,真正值得我们欢呼的GeForce4终于来了。
平凡的命名规则
以前讲过ATi的Radeon系列的命名原则之后,很有些背下了元素周期表的“成就感”。这一回让我们来看看更加浅显易懂的“GeForce周期表”。
首先可以肯定的是Ti这样著名的“太空金属”,让NVIDIA的销售更有号召力和凝聚力,而MX这样的低端品牌也早已深入人心。所以NVIDIA从GeForce4开始,高端的主力产品(代号为NV25)全部使用Ti这样耀眼的名称,而面向大众市场的普及型产品(代号为NV17)则一律使用MX这个通俗的名称。((图2))

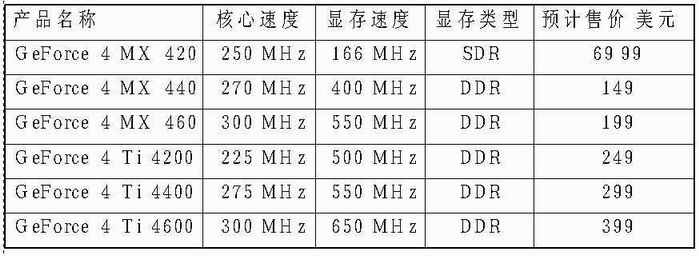
字母后面还要有数字,这就区分了不同系列、不同产品的档次:第一位是表示第几代的GeForce;第二位是同系列产品中的区分,数字越大性能就越高;再后面就是为了好看、好读的“0”。Ti比较“高贵”,所以数字较大、分到了两个“0”,而较廉价的MX只有一个“0”。这么说比较枯燥,看一看下面的表格就明白了:(图1)
改进的核心设计
这次GeForce4仍旧使用0.15微米制造工艺,但是对于GeForce4 Ti这样集成了6300万CMOS管的超大型设计来说,0.15微米制造工艺的耗电量和热耗散都是大问题:显然在采用0.13微米制造工艺之前300MHz核心频率已经几乎是物理极限了,所以NVIDIA专门为GeForce4 Ti芯片配备了PBGA封装和内置散热器;而且大面积的硅核心必然明显降低成品率,导致价格居高不下,也难怪NVIDIA搞出这么多低频率的中低档型号。
在传统的3D流程中,GeForce4相对GeForce 3没有什么明显的进步,GeForce4 Ti还是标准的第二代T&L引擎加上4条双纹理的渲染管道,GeForce4 MX据称也是类似的设计,但是只有两条渲染管道。((图3))

但是NVIDIA从X-Box计划中得到的技术优势并不在这里,GeForce4 Ti从X-Box继承来的正是双Vertex Shader无可匹敌的多边形生成率(渲染能力倒是只有小幅提高),而且核心运行频率还比X-GPU更高。这说明3D领域多边形性能的重要性正日益凸现。((图4))

GeForce4 MX则是GeForce2 MX的加强版,并不具有Vertex Shader和Pixel Shader,只不过采用了高频率的DDR显存,还增加了一些GeForce4 Ti才有的新功能,这说明本来GeForce 3 MX的名称也许更合适些。说实在的,削减了核心性能的GeForce4 MX系列的性能本应比不上GeForce 3才对,只有在比较传统的3D游戏中才可能因为显存频率比较高占到一些便宜,所以只能指望GeForce4 MX便宜些才会好卖──再看看NVIDIA决定停产GeForce3标准版和GeForce3 Ti 500的消息就更加证实了这一点。
闪亮的全新功能
GeForce4 系列具有几种比较新颖的特性,GeForce4 Ti具有Accuview精确反锯齿、LMA Ⅱ光速内存架构二代和nView多头显示功能,GeForce4 MX则具有Accuview精确反锯齿、缩减版LMA Ⅱ光速内存架构、nView多头显示功能和VPE视频处理引擎。
Accuview精确反锯齿
这其实仍是用两个取样点达到4X FSAA的另一种尝试。过去GeForce 3称作HRAA(高分辨率反锯齿)的Quincunx采样方式是将第一个采样点放在目标像素的中心、第二个采样点放在像素的一角,现在Accuview的方式是将两个采样点均匀地分布在目标像素的内部。这似乎称不上多么大的改进,同ATi不规则的可编程采样方式相比并没有什么优势,而且GeForce4 MX也不具备足够的实力在高分辨率下运行Accuview,但看来这次NVIDIA硬是把Accuview作为GeForce4的主要卖点来推广。
LMA Ⅱ光速内存架构二代
这个功能解释起来还真是复杂,基本上说LMA就是将DDR显存接口的256位数据改由4个内存控制器分别控制,这样的灵活性带来了接口利用率的提高。LMA Ⅱ也是同样的设计思想,GeForce4 Ti仍是4个64位内存控制器,GeForce4 MX则使用比较简化的两个128位内存控制器。二代的进步是通过集成的专用缓存提高效率,可以利用更少的带宽去除更多的无用像素。二代的Dual Texture Caches使用新的算法提高预测的命中率,可以明显改善3、4重纹理的贴图效率。
nView多头显示
GeForce4系列芯片都内置了用于CRT显示器的双350MHz的RAMDAC,以及用于LCD显示器的双TDMS发送器,因此可以直接支持各种配置的双显示器。nView相对于GeForce 2 MX的TwinView只不过是名称的变更而已,唯一的进步是RAMDAC和TDMS全都是集成的了。想不到又一代产品还是使用350MHz的RAMDAC,难怪Matrox始终认为自己的360MHz的RAMDAC是最好的,而且短期内不用升级──看来2D显示的精度就要到极限了,而NVIDIA这次对2D质量还是不会有多大的提高。
VPE视频处理引擎
这是GeForce4 MX独有的功能。首先是支持完全的DVD硬解压,这是NVIDIA第一次支持硬件Idct,尽管ATi早在Rage 128的时代就已经有了;另外GeForce4 MX集成了完整的视频输出功能,尽管输出图像质量的提高并不明显。
另外还有两件事情有存疑。一是新一代的DDR内存全都是BGA封装,可是GeForce4用的是长方形三星DDR SDRAM,而ATi的FireGL 8800/8700专业显卡用的是正方形的亿恒DDR SGRAM,到底哪一种更快、更稳、更能超频?二是新一代的NVI DIA专业卡NV25GL应该是Quadro 4还是Quadro DCC Ⅱ?如果还是走联合3DS MAX的老路,在ViewPERF中肯定不是FireGL系列的对手,更不要说新一代专业3D之王Wildcat Ⅲ 6210/6110了。
谁能傲视天下
可以肯定,GeForce4 Ti 4600是当前速度最快的游戏用3D显示卡。谁能挑战NVIDIA无敌的地位呢?ATi肯定是第一挑战者,笔者并不认为R300能在近期推出,因为下一代的ATi必然兼容DirectX9,只能是尽快推出R250来挑战GeForce4 Ti 4600。KyroⅡ Ultra如果真的有T&L引擎,肯定有实力同GeForce4 MX 460一决高下,不然又只能等待KyroⅢ了(希望不要像我们等待Bitboys的Glaze3D那样总是失望)。还 有清晰度和色彩之王Matrox,谣传其下一代产品Parhelia(幻日)……
无疑GeForce4 Ti最大的优点是史无前例的多边形速度,相对而言ATi的TruFORM反而曲面技术的代表──最具讽刺意味的是NVIDIA一向是全力倡导曲面技术却应者寥寥。从长远来看,未来ATi与NVIDIA之战必将成为曲面和多边形之间的决斗;而目前,大家比拼的仍是核心/显存频率,了无新意,唯一特别需要注意的是驱动程序的质量决定了显示卡的实际表现和用户的最终感受。
注:有关NV17显卡的评测请参阅本期H版硬件评测。