2002年64位计算时代的到来
硬件周刊
编者按:现在就讲64位计算技术会不会太早了点?其实并不算早,虽然目前64位计算技术主要应用在服务器类高端计算机设备上,但随着技术的更新以及新一年的到来,科技的脚步将会越来越快,让我们一起走进64位计算时代!(注:字长指运算器支持参与运算的2进制数位数,长较长的CPU的运算能力较强,80386以后的x86系列CPU均采用了32位字长,64位的CPU级别更高。)
现状
去年,处理器的发展速度是有史以来最快的,不仅涌现出了许多新产品,而且AMD的1.63GHz Palomino K7(AthlonXP)达到了Pentium 4 2GHz CPU的水平,让人们重新考虑高频率CPU的价值。Pentium 4采用全新的x86架构,本来是一件好事,但0.18μm的旧工艺不能完全发挥其功效,因此,英特尔最近推出了0.13μm Northwood新P4内核,二级缓存从256KB提升到512KB,在时钟频率和内核方面同时用功,准备再次摆脱Athlon芯片。
当然,Athlon和P4都只是32位处理器,真正使我们感到兴奋是各厂商的64位处理器,英特尔提供了McKiney,AMD发布了Hammer,两者市场定位不同,没有直接进行竞争。英特尔真正要面对的是IBM、Compaq等巨头,IBM的 Power 4将达到1.3GHz,Compaq的teaser采用EV7总线作为最新的Alpha推出,它们的内存和输入/输出带宽都相当惊人,以应付日益繁重的商业工作。Sun继续发展UltraSPARC-Ⅲ产品线,引入铜线连接技术,避免了以前铝线连接产生的预获取缓冲的bug,经过优化后还能让浮点性能上升不少。另一方面,还有新一代SPEC(System Performance Evaluation Corporation,系统性能评估测试)处理器测试软件SPEC 2004的消息,下面一起来进入64位计算时代吧。
McKinley
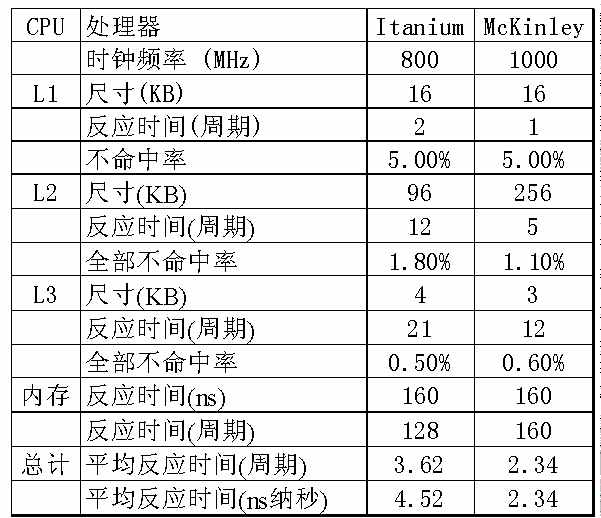
更多逻辑单元和更多缓存是对McKinley的最好概括,其内核尺寸和晶体管数目均高于Itanium(Merced内核),采用0.18μm工艺,220M(百万)晶体管共占用了465mm2。McKinley主要把晶体管花费在L3 Cache身上,成为第一个包含三级缓存的64位芯片。一级缓存分为16KB指令和数据缓存,二级缓存是统一的256KB架构,三级缓存为令人惊叹的3MB,((图3))是各种典型微处理器的基层设计对比图。
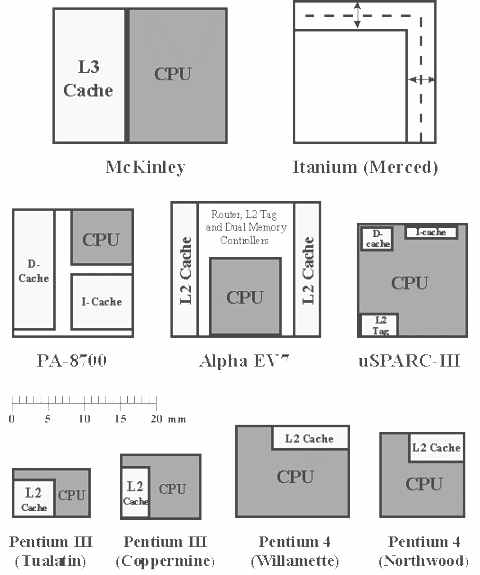
注:Itanium只知道内核尺寸,其余部分为英特尔没有公开的保密信息,无法进行缓存容量对比。
第一代IA64 Itanium和第二代IA64 McKinley都使用了六流水线按序执行处理单元,由于按序执行不能越过延迟指令,低平均内存反应时间对性能起着至关重要的作用。在相同的铝线CMOS处理下,片内三级缓存的速度比Itanium的外置三级SRAM要快,一级和二级缓存也快25%~50%,才能保证McKinley性能超越Itanium。((图4))
内存反应时间的改善,正好与英特尔在技术论坛会议上宣称的相同,然而,结合所有缓存的不命中率后,平均内存存取时间都只是160ns。
增强缓存容量后,CPU的指令载入速度得以提升,McKinley约是Itanium的一半。性能提升固然是好事,但伴随大内核而来的是成本增加,幸好减少了板卡和安装模块的尺寸、功耗和发热量,总体来说成本增加不多。与之对比的是基于EV7的可缩放型系统,使用能支持高反应时间的乱序执行架构,利用高性能内存控制器来弥补小缓存的不足,同样能达到近似的效果。
除了增强缓存性能外,McKinley还引入了两个额外的内存单元,能够完成大多数整数运算的内存操作,简化指令分派和减少资源占用。按照IA64的官方描述,整数单元和内存单元能够执行简单的ALU操作,如:加、减、对比、位逻辑运算、简单跳转和一些整数SIMD指令,其中整数单元甚至能执行需要长时间使用功能单元的罕见操作,如:普通跳转、位区域插入和抽取、入口计数等。
由于内存单元很少执行整数指令,为了节省硅片消耗量,McKinley仅增加了两个内存单元(共四个),并且维持整数单元的数目为两个。不同整数操作的相关数据,大约有90%能够让内存或整数单元任一个来执行。假设我们随机挑选六个整数操作,其中每个由内存单元执行90%,有98%的机会把六个指令加入MMI+MMI双重发送包,因此增加额外的整数单元,并不会对性能有多大提升,英特尔维持原状的做法是正确的。
McKinley的基本执行管道是八层,比Itanium短两层,有传言说新的IA64内核使用了原来的Alpha EV8设计组的发展思想,会遇到某些管道传输问题,然而,这种说法没有得到任何正式确认,暂时无法辨其真伪。
Hammer
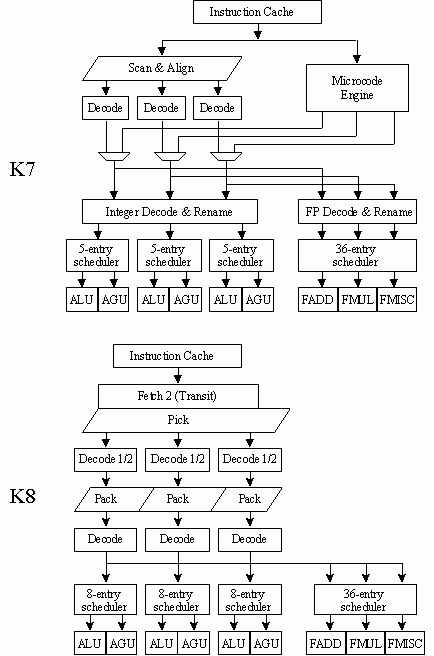
K8把x86带来64位世界,扩展了原来的x86指令集,不像IA64般使用全新的指令集,保证了向后的兼容性。x86-64的特点是支持64位平行寻址,64位GPRs(General Purpose Registers,通用寄存器),K8的内核设计源于K7,两者的后端执行单元基本相同。
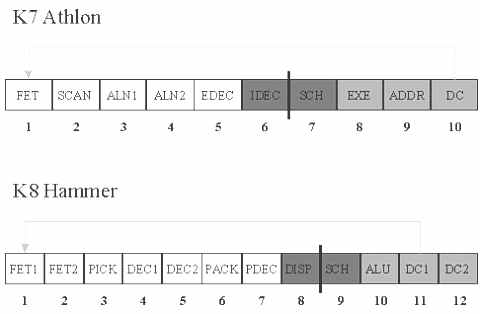
整数调度从五个操作提升到八个操作,增加的整数乱序指令调度,主要用于数据缓存两个周期的载入使用反应时间,增加了每个时钟的处理性能。接着是基本执行管道的比较:
K8的执行管道比K7多了两重,主要用于x86指令解码和微操作分派到整数和浮点调度程序。尽管某些层的名字改变了,实际用途却是一样的。K8可以完成大多数复杂和困难的任务,如:三个不同长度并行指令的获取和解码它们的内部操作,执行引擎比传统的乱序执行RISC(Reduced Instruction Set Computing,精简指令集计算机)要复杂几倍。因此,Athlon的错误预测花费是十个周期,K8增加了十一个。
AMD曾指出,Hammer努力改善了K7在基本块设计和执行管道方面的不足,额外的管道可以增加内部操作的灵活性,减少延迟现象,增加IPC(Instructions Per Clock Cycle,指令/时钟周期)。相对于K7来说,最明显的改善在于减少每层的工作量。虽然缺少详细的资料,无法了解K7与K8之间前置管道层的变化,但起码可以明白增加管道对提高时钟频率有很大好处。((图5))
虽然64位指令集让人感到很好奇,但Hammer真正的性能提升源于架构的改变。它集成了HyperTransport(HT)内部处理通讯接口和64/128位高性能内存控制器,提高总线数据交换和非缓存/注册型内存的速度。K8最多可以支持八条DIMM槽,满足高端服务器对内存的需求,以较低的内存速度来换取大容量,方便人们在速度和容量中取得平衡。K8在提高速度的同时,发热量没有提升太多,因为使用新制程降低了功耗。(图1)
McKinley和Hammer都是64位芯片,但面向的市场大不一样,McKinley主要目标是中高端服务器,而Hammer家族的第一个成员Clawhammer却是对应高端桌面电脑。当然,这并不意味着McKinley好于Hammer,很可能会再次上演P4挑战AthlonXP的情况,ClawHammer将打败高时钟频率的IA64。
AMD声称,Hammer可以提供比现有内核快两倍的SPEC 2000整数得分。此说法非常含糊,是比AMD最好的快?还是比最好的x86芯片快,是ClanHammer有这种能力,还是缓存更大的Sledgehammer有这种能力?现在没有任何正式的测试报告出台,芯片还处于除错和校验之中,不过,模拟架构测试的资料显示,Hammer的SPEC 2000可以达到1400分,这已经是一个了不起的成绩,敬请期待吧。
Alpha
Compaq宣布Alpha架构停止,整个EV8开发组将转到英特尔,但是EV7却没有因此而停滞不前。其优异性能在2002年年中才正式显露出来。由于新的架构非常重要,并且需要集成芯片组功能,所以EV7的开发变得非常缓慢,为了保证当前产品和EV7之间的兼容,Compaq决定在近期发布EV68 1.25GHz过渡版芯片。
尽管EV7的设计架构已经公布了将近三年,但关于路由和内存控制方面的技术最近才揭晓,性能方面还算可以,0.18μmEV7的SPEC 2000整数得分为804、浮点得分1253,带宽为5GB/s,可以和时钟频率更高的Power 4相比。未来的0.1μmEV79要更强一些,但Compaq是否提供支持暂时还是一个疑问。
UltraSPARC-III
Sun最近推出了UltraSPARC-Ⅲ家庭的新成员,900MHz Cu芯片,用于Blade 1000 Model 1900机器。用铜线互连代替了原有的铝线互连,提高速度。除此之外,为了消除原有的预获取缓冲错误,本来,在旧的SPARC芯片中可以在固件中禁止这项特性来换取兼容性,不过,这让SPEC浮点得分从427下降到369分,所以Sun不得不加快工作进度,推出新的处理器。Model 1900与以往的Model 900一样,都使用了8MB超大容量二级缓存。
Model 1900与Model 900的最大系统级硬件差别不仅仅是预获取缓冲技术,Sun使用Forte 7 EA编译器代替Forte 6亦非常重要,使其浮点性能有较大变化,看看(图6)即可明白。
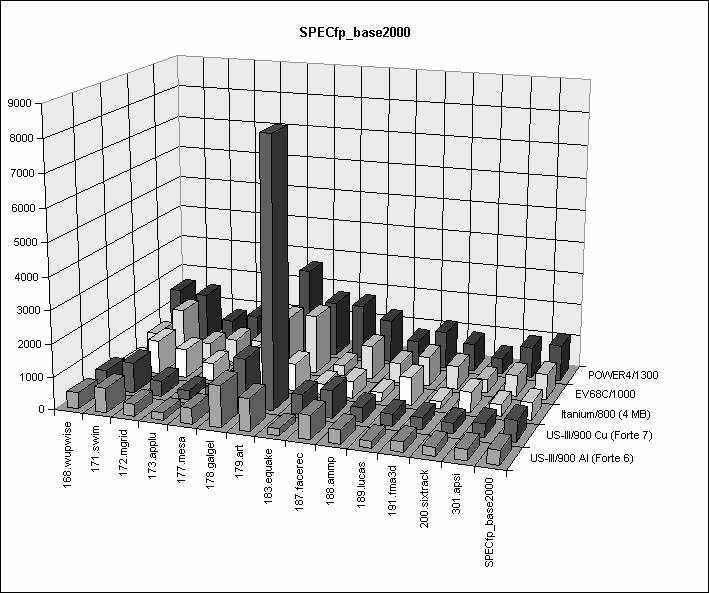
SPEC fp_base 2000,浮点基本测试由14个子程序组成。与之对比的还有Itanium(4MB缓存,HP i2000的800MHz版本)、Alph a EV68C(ES45/1000的1GHz版本)和Power 4(pSeries 690 Turbo的1.3GHz版本。)
同是UltraSPARC-Ⅲ 900MHz芯片,采用不同编译器竟然会有如此大差别,真让人感到惊奇。183.equake的增益是300%,179.art更超过800%,比Alpha EV68和Power高4倍,这是Forte 7编译器的最主要变化。如果忽略这个改变,总分将会从629降至516,差额约为18%。
令人注目的179.art测试得分,使UltraSPARC-Ⅲ的性能增加许多,观察家和竞争对手马上怀疑起它的实际用处,很长一段时间内,人们都在讨论是否Forte 7为测试软件进行优化而获得如此高性能。还记得当年英特尔的编译器的bug曾经让SPECint92的整数测试得分提升10%吗?该bug只对023.eqntott得分进行优化,普通应用时毫无用处,所以179.art得分让人感到虚假,也有一定原因。
179.art使用FORTRAN和可改变的C语言写成,利用逆转工程学,并使用内置循环的方法进行优化。FORTRAN和C存取相反列和行的两个二次元队列,假设179.art存取队列在内部循环错误索引时会导致较低的缓存命中率,Forte 7编译器可以识别这种情况,通过嵌套循环来让队列进行内部存取,就能提高缓存的命中率。
优化仅会对SPEC起作用,如果想作用于其他程序,那些程序必须大于单独的SPEC基准测试或测试套件本身。简单地说,作弊只对测试软件或某些特定程序有效,厂商没有遵守游戏规则的做法,会降低SPEC程序的可靠性,也说明了测试软件本身不足,有必要尽快完善并发布SPEC 2004。不过,现在还没有确实证据认定UltraSPARC-Ⅲ900 Cu使用了特殊优化法,我们还是不要过早下结论为好。
结论
微处理器之战越演越烈,英特尔和AMD正式开始短兵相接,0.13μm的Northwood P4已经上市,0.13μm的Athlon XP及其SOI版本也会在近期推出,在64位Hammer发布之前,AMD都会极力争取性能王者之位。英特尔与AMD的市场策略不同,它准备把64位芯片定位于高端市场,借助对Itanium的部分改良和大容量缓存,获取更多的利润。
以前,在微处理器中集成高速链路和内存控制器,只是高端芯片的专利,然而,此类技术却慢慢过渡到台式机领域。虽然它应用的范围有限,但能有效地提高性能和减少内存存取时间,也可以降低多处理器系统的成本,厂家何乐而不为呢?
在高端领域中,各厂商为了巩固自己的地位,不断开发新产品,以提高SPEC测试得分为目标。其中,以Sun的表现最为出色,可以让新UltraSPARC-Ⅱ得分提升高达20%,真是前所未有的重大改善,但希望能在实际应用中真正有用处。Power 4和Alpha也各有进步,业界巨子们不会眼看着英特尔和AMD的逼近而坐视不理,毕竟,高端市场才是获利最多的地方,已经吃到嘴的丰盛晚餐可不能随便分人。(图2)