|
| 当前位置:电脑报电子版 > 1999 年 > 24 期 > 软件世界 > 谈Office 2000的字符编码技术 |
| 《 谈Office 2000的字符编码技术 》 |
| 微软公司的办公套件Office97针对不同语言有各种不同版本,当你要使用一种语言进行文字编辑时,需安装相应语言版本的Office才能有最好的支持和兼容性,另外很多时候不同语言也不能在文档中同时正确显示。不过在即将推出的Office2000中,这些问题将得到解决,全世界的用户都只需安装同一个版本的Office2000,然后通过选择不同的语言包就可以得到不同的界面和语言支持,并且包含不同语言的Office文档也不会再有兼容性的问题。而这一切的实现,一个很重要的原因是Office2000提供了真正的全球性的Unicode支持。
操作系统的字符编码 1.编码方式 微软最初的操作系统MS-DOS只支持256个字符, 微软最初的操作系统MS-DOS只支持256个字符,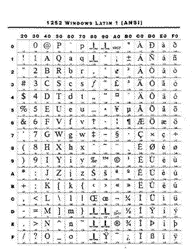 其中包括26个英文字母(大小写两种形式都有,即实际共有52个)、标点符号、希腊字母、画线符(用于基于MS-DOS的应用程序画框)和一些重音字符,即扩展ASCII码(扩展美国国家标准交换码,其中前面从0-127是标准ASCII码,后面的为扩展字符)。随着计算机的日益普及,为了让用户能用自己的语言在计算机上操作,于是增加了很多的代码页,每种代码页支持一种语言,单字节代码页中代码从32到127(十六进制0x20~0x7F)间的字符都是标准ASCII码,其他的则是根据所支持的语言不同而不同的相应的扩充字符。当操作系统进入Windows时代后,用代码页来支持不同语言的方法被保留了下来,从Windows3.1到Windows95使用的代码页是相同的,而Windows98在原ANSI字符集基础上有了变化。扩展ASCII码表和Win95 ANSI字符集见图一和图二所示。 其中包括26个英文字母(大小写两种形式都有,即实际共有52个)、标点符号、希腊字母、画线符(用于基于MS-DOS的应用程序画框)和一些重音字符,即扩展ASCII码(扩展美国国家标准交换码,其中前面从0-127是标准ASCII码,后面的为扩展字符)。随着计算机的日益普及,为了让用户能用自己的语言在计算机上操作,于是增加了很多的代码页,每种代码页支持一种语言,单字节代码页中代码从32到127(十六进制0x20~0x7F)间的字符都是标准ASCII码,其他的则是根据所支持的语言不同而不同的相应的扩充字符。当操作系统进入Windows时代后,用代码页来支持不同语言的方法被保留了下来,从Windows3.1到Windows95使用的代码页是相同的,而Windows98在原ANSI字符集基础上有了变化。扩展ASCII码表和Win95 ANSI字符集见图一和图二所示。2.存在的问题 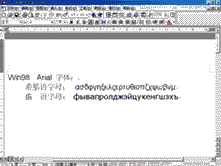 由于代码页使用的是单字节字符集(SBCS),即每个字符都是用一个字节来表示,所以代码页能包含的字符最多只有28=256个, 由于代码页使用的是单字节字符集(SBCS),即每个字符都是用一个字节来表示,所以代码页能包含的字符最多只有28=256个,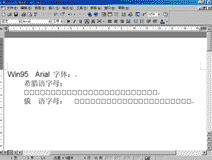 这对于使用字母的语言够用了,但像中文这种表意字符,每个字都要占用字节,而常用汉字怎么也有两三千个,单字节字符集显然就无能为力了。于是很自然地出现了双字节字符集(DBCS)。在DBCS中,大多数字符(表意字符)由两个字节构成,但同时也存在只占一个字节的字符,比如ASCII码和日文片假名等,DBCS的缺点也就由此而生了。当你如往常一样使用strlen函数想知道一个DBCS字符串中的字符数时,得到的结果只是该字符串中的字节数。虽然Windows提供了一些诸如CharNext、CharPrev、IsDBCSLeadByte之类的函数来帮助处理DBCS字符,但对于程序员来说,处理字符串时总是要判断一个字符是一个字节宽还是两个字节宽,这无疑是在做一场恶梦。 这对于使用字母的语言够用了,但像中文这种表意字符,每个字都要占用字节,而常用汉字怎么也有两三千个,单字节字符集显然就无能为力了。于是很自然地出现了双字节字符集(DBCS)。在DBCS中,大多数字符(表意字符)由两个字节构成,但同时也存在只占一个字节的字符,比如ASCII码和日文片假名等,DBCS的缺点也就由此而生了。当你如往常一样使用strlen函数想知道一个DBCS字符串中的字符数时,得到的结果只是该字符串中的字节数。虽然Windows提供了一些诸如CharNext、CharPrev、IsDBCSLeadByte之类的函数来帮助处理DBCS字符,但对于程序员来说,处理字符串时总是要判断一个字符是一个字节宽还是两个字节宽,这无疑是在做一场恶梦。
不能同时正确显示多国语言的原因 因为Windows 3.X每次启动时都是载入与其版本相对应的代码页,即只支持单一代码页(DOS也一样)。其中除了ANSI字符集、相应的DOS字符集,就只有该版本代码页中所支持语言的字符了,而对于使用这些字符集之外的语言自然就无法被调出来显示了。Windows 95为了支持混合语言,采用了大字体。在大字体中通常包含多种字符集,如GBK字体中就包含了采用GB码和BIG5码的汉字。不过Win95中大字体的使用还不普遍,大字体需单独安装。在Windows98中,开始支持称为Extended Windows ANSI(也称为WGL4)的字符集,该字符集包含了652个字符,除了标准ANSI字符外,还有俄语、希腊语、土耳其语等多种语言的字符,大字体技术虽然向多语言支持迈进了一步,但仍然脱离不了代码页的映射和转换,所以一旦文档被另存为不带格式的纯文本,被转移到另一台没有安装多语言支持或相同字体,文档的显示结果将会是部分字符无法显示或乱码一堆。这种情况在如今大量通过网络进行信息传递的时代屡见不鲜,也是使用代码页技术的最大弊病。图三和图四表明了用Win98 Arial字体可正常显示的希腊字母和俄文在换用Win95 Arial字体后全部无法显示。Unicode字符编码的原理 Unicode简言之就是宽字节字符集。在Unicode中,每个字符都固定使用两个字节来表示,这样一来,在字符串中只需简单地通过加减指针就能访问一个完整的字符。由于Unicode中字符都用16位(即两字节)的值表示,所以可以表示的字符最多有216=65536个,这样一来,几乎全世界所有书面语言所使用的所有字符都能被包含进来了。即使如此,所有的字母和符号加起来也才用了约35000个代码点,至今大约还有29000个代码点未被分配,保留作将来使用,这其中又有6500个位置是留供用户添加所需的自定义字符,一般是一些罕见的代表人名和地名的象形文字。Unicode的编码布局见图五。Unicode力图让每个被编码的字符用途都是唯一的。例如,常见符号“-”,可以是连字符,也可以是减号,因两者的用途完全不同,所以即使外观一样,但在Unicode中仍各有编码,并通过使用略微不同的宽度来描绘它们。不过对于中文和日文中的相同汉字,却又是使用同一编码,因为Unicode不能区分字符在语义和读音方面的区别,不管这个字是什么意思,怎么读,反正是用来表达意思的一个表意字符,这样做到了汉字的统一。也正是由于Unicode相当于一个单一的字符集,所以不再有多内码页的映射和转换问题,使用Unicode编码方式的文档无论使用哪种Unicode字体来显示都是一样,乱码不会再有了,唯一可能出错的地方就是字体中包含的字符不完整。 Office2000字符编码的秘密 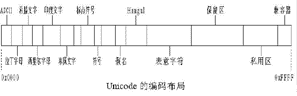 由于Office2000全面支持Unicode,则源程序中涉及字符串处理的函数都能接受16位,而且是Unicode编码的字符串参数。因为以前非东亚版本的函数可能对其中的字符串参数是用char关键字定义的,这样实际规定了参数只能是8位,现在用short关键字定义,就能接受16位的值了。而且一般函数接受的字符串都是ANSI字符串,因为与Unicode编码方式完全不同,所以要想处理Unicode字符串参数,对字符串的处理也必须做改动。以前之所以有那么多不同的版本,主要就是为了适应当地的字符集,有了全球统一编码的16位Unicode字符集,可以直接适应全球用户,不再有单、双字节和不同代码页的混合处理问题,不需再对核心程序做修改,也就实现了全球版本的同一性。 由于Office2000全面支持Unicode,则源程序中涉及字符串处理的函数都能接受16位,而且是Unicode编码的字符串参数。因为以前非东亚版本的函数可能对其中的字符串参数是用char关键字定义的,这样实际规定了参数只能是8位,现在用short关键字定义,就能接受16位的值了。而且一般函数接受的字符串都是ANSI字符串,因为与Unicode编码方式完全不同,所以要想处理Unicode字符串参数,对字符串的处理也必须做改动。以前之所以有那么多不同的版本,主要就是为了适应当地的字符集,有了全球统一编码的16位Unicode字符集,可以直接适应全球用户,不再有单、双字节和不同代码页的混合处理问题,不需再对核心程序做修改,也就实现了全球版本的同一性。遗憾的是Win9X对Unicode的支持还很不完善,它仍然使用代码页方式,所以为实现多语言功能,在Office2000中还要安装相应的语言包。 国产软件要到国际市场去竞争,使用Unicode应该是一条必经之路,这样软件不仅进行国际化时的工作量会小得多,更主要的是能有很好的适应能力。其实我认为Unicode最有用的地方应该在网络中。当Unicode得到普及后,无论你访问哪种语言的网站,查看哪种语言的文档,都能得到正确的显示,不会再有乱码出现,到那时大概就是网络世界的大同时代了吧。 (四川 关 涛) |
| 下载本期推荐软件 | 页 首 |
| 《电脑报》版权所有,电脑报网站编辑部设计制作发布 |