 |
|
| 当前位置:电脑报电子版 > 1999 年 > 18 期 > 硬件周刊 > 高性能CPU的秘密――超标量CPU篇 |
| 《 高性能CPU的秘密――超标量CPU篇 》 |
| CPU具有高时钟频率当然很好,但这并不是使处理器速度快如闪电的最主要原因。实际上,即使你把386运行在500MHz下,它也不比PⅡ-233更快。怎么样,你想知道K7为什么是一款很有前途的CPU吗?为什么PⅡ比Pentium更先进? 本文将向你解释这些新一代CPU比其前代CPU更快的真正原因。 在微处理器时代来临之前,CPU设计者加速CPU的方法是让下一代CPU能够在更少的时钟周期内执行确定的几个指令。Intel 8088 CPU执行“MUL”(逻辑乘)需要133个时钟周期才能完成!Intel 486减少了所需要的时钟数,把两个16位整数的“MUL”指令减少到13个时钟周期。这就是为什么286比8088快,386比286快的原因。当时采用的方法虽然简单,但却很有效。当然,那些CPU都是“史前恐龙”了,现在让我们来看看现代的CPU。 一、更多的流水线 当Intel发布486时,Intel也同时带来了首款采用流水线技术的X86 CPU。如果你读过上篇文章(见今年12期17版),你就知道流水线技术的优越之处了,虽然指令的潜伏期延长了,但却能使CPU在每个时钟周期都有指令输出。你也许要问,既然流水线有这么多好处,为什么不再多用一条呢?对的,Intel也这样认为,所以Pentium出世了。Cyrix的6x86系列CPU也使用了“双流水线”架构。 Pentium内部主要的流水线是“U-Pipe”,能应付所有的X86指令;另一条流水线称为“V-Pipe”,只能对一些简单的整数指令和一个浮点运算指令“FXCH”解码。当然,为了充分使用第二条流水线,就得为Pentium架构专门优化编译器,经过这个编译器编译的程序在Pentium上的运行速度几乎是同频率486的两倍。 二、RISC的威力 在1995年,一个名叫NexGen的公司(后被AMD收购)认识到X86指令集是提高CPU性能的一个很大的障碍,因为X86指令的长度和格式都各不相同,会造成解码困难。于是他们开发出了NX586(AMD在NX586的基础上开发出了K6核心),NX586在相同时钟频率下的运行速度比Pentium快,秘密就在于它把那些长度不定的X86指令集翻译成了短小且长度固定的类RISC指令。新一代X86 CPU诞生了。这些CPU使用了同RISC CPU一样的性能增强手段。几乎同时,Intel也得出了同样的结论:Pentium Pro就具有一个快速的RISC核心,后来的PⅢ、PⅡ、赛扬等CPU都是在这个核心(P6)上繁衍出来的。P6核心的速度更快,具有更长的流水线,让我们来看看P6 CPU的数据通道(见图1)。 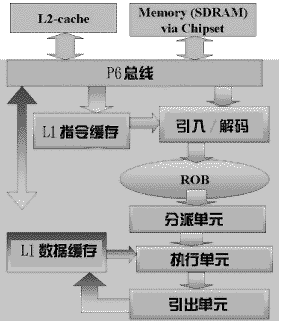 引入单元(Fetch Unit)能够提前从一级指令高速缓存(L1-I-cache,P6核心将一级缓存分为指令缓存和数据缓存,K6也是这样)中预取30条指令; 解码单元(Decode Unit)则很忙,它必须将那些“粗野”的X86指令“驯服”成“优雅”的RISC指令。它解析出X86指令的长度,并把指令排列整齐,最后将它们翻译成类RISC微指令。在PⅡ上,光是对X86指令的引入和解码就要消耗7个时钟周期,这会带来一些麻烦。 微指令在被执行前先存放在“重排序缓冲器(ReOrder Buffer,ROB)”中,一个分派单元或预约单元(Reservation Unit)将这些微指令分送到不同的执行单元(Execution Unit)中,执行单元同时从一级数据缓存(L1-D-Cache)取得所需的数据进行计算,然后将结果送回ROB和引出单元(Retire Unit),并被写到正确的寄存器中。 三、更多的执行单元 既然两条流水线的性能比一条好,为什么不造四条呢?OK,让我们看看一条带有5条小流水线的大流水线(见图2),我们可以把PⅡ或PⅢ的引入和解码单元作为一条大流水线,它在每个时钟周期中可以对3个X86指令解码,能够满足后面的5条小流水线(Intel喜欢称之为“port”)的要求。这是由于解码单元的能力较强,而且由于预约单元有时在将指令发向所需的执行单元时,该执行单元正忙于处理其他指令,因此要求有足够数量的执行单元来满足要求。 PⅡ或PⅢ能够在每个时钟周期中最多对3个 X86指令解码,所以我们称它为“3路超标量CPU”。超标量的意思就是同时可以处理超过一个以上的指令。 K7也是一个3路超标量CPU,它的解码单元是通用的,可以毫无限制地对任意3个X86指令解码。PⅡ或PⅢ有一个强悍的通用解码单元和两个只能对简单X86指令解码的解码单元。相对而言,K7能够保持较高的平均解码率。据一份微处理器报告声称,K7的实际平均解码率可以达到每个时钟周期2.5个X86指令,PⅢ则只能达到每个时钟周期2.1个,K6-Ⅲ或许可以达到1.9个。K7具有9个执行单元,而PⅢ只有5个,而且K7有一个更大的缓冲器和一个128K的一级高速缓存,所以K7比PⅢ更接近达到每个时钟周期3个指令的速度。 当你读了上面的文字后,你也许会想到,终极CPU是很容易设计的,把许多解码器、更多的执行单元、更长的流水线放进CPU中......瞧,Pentium Ⅵ或K11不是就出来了吗?可是,如果任何时候只有一个甚至三个解码单元忙于处理指令时,一个具有8个解码单元的CPU就会造成非常严重的资源浪费。为什么我们不充分挖掘CPU的潜能呢? 四、艰难的选择 首先,实际运行的程序充满了分支,看看下面这个例子: 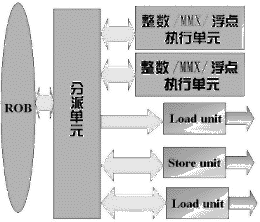 if (i==0) A=1 else A=2 把程序解释成CPU指令,就是: 1.比较i和0; 2.如果不相等则跳到“Else”处; 3.然后把1赋值给比变量A; 4.跳到“Else”的下一步; 5.Else:把2赋值给比变量A; 下一步。 这里有一个比较令人头疼的问题,流水线技术的采用固然能大幅提高CPU的性能,但解码是在引入指令后执行的,当CPU引入第3条指令时,解码器正对第2条指令解码,在上述例子中,如果“i”不等于0时,情况是怎样的呢?当我们引入指令3时,同时却跳到“Else”(第5条指令)处。这就是流水线的问题,CPU引入了指令,但却不知道在解码完成后它将做什么?同样的问题也会发生在指令4上,即使是一个无条件转移(即你不需要做任何检测工作),指令5也会在需要前被引入。 你也许还看到了更大的问题,当我们想要执行指令2时,需要指令1的结果。哪条分支是我们需要的呢?是指令3还是指令5?因此,我们只能等待指令1的完成。PⅢ有12个工位(K7有10个),这意味着一个指令要在12个时钟周期后才能完成。是否我们一定要在指令1完成后才能发布下一条指令呢?我们是否一定要把指令3拦住不放呢?现在一般认为,X86程序中条件分支指令(IF语句)平均占了20%,所以上述问题在高性能CPU中是不能接受的。我们必须提前对分支程序进行预测,而不是坐等条件判断的结果。 五、分支登记表 绝大部分现代CPU具有一个logbook(分支登记表),表格中包含了CPU在执行程序时所遇到的每个条件分支程序的入口。这个历史表格可以简单地认为由两列组成,第1列包含了分支指令的地址,第2列是一位指针,标示最近分支是否发生。如果预测出错,位指针就会改变。有一些历史表格采用了两位指针,用来标示分支是否发生,下一次是否会遇到。为什么要采用两位指针呢?因为只有在预测出错两次后,我们才会改变预测结果。举例来说,第1位是“1”,即分支发生,第2位也是“1”。下一次,分支没有发生。第1位仍然是“1”,但第2位变成“0”,如果再下一次分支仍然未发生,第1位则变为“0”,意味着分支没有发生。 实际的程序包含了一小部分最被频繁调用和执行的分配代码:“过程”和“函数”,一个过程经常被调用,比如游戏中的检测用户输入(键盘、鼠标和游戏杆等)过程,这些过程包含循环程序(如重复执行相同代码10次),而循环程序中又包含了分支代码,这些分支总是经常发生,只是在结束时才按顺序执行(或者相反),如果我们只是因为一次预测出错就改变指针,那么在那种特定过程中就可能每次预测出错。 不过CPU采用的历史表有许多不同,K6-Ⅲ的历史表类似上述两位表,PⅡ的表格第一列中并未存入分支指令的地址,而是存入跳转后的目标地址。 六、小结 为什么要关注分支预测呢?你知道,要想使CPU工作在高时钟频率下,必须延长流水线,但是,流水线越长,预测出错后的等待实际运算结果的时间也越长,因此,你必须“清洗”流水线来消除错误。有人指出,在PⅡ/PⅢ上,一个预测错误会浪费掉11~15个时钟周期。具有6工位的K6在分支预测出错时浪费的时间要少一些,只有4个时钟周期,高达95%的预测正确率(PⅡ为90%)也是让K6-Ⅲ在商业应用程序中比PⅡ强大的另一个原因。但是,在具有更长流水线的K7上,预测错误造成的停滞将超过4个时钟周期。 不浪费时钟周期是很重要的,但我们怎样才能确信所有那些昂贵的执行单元一直都在努力工作呢?下一次,我们将讨论“乱序执行(Out-Of-Order execution)”、“按序执行(In Order execution)”、“寄存器重命名(Register Renaming)”和“投机执行(Speculative Execution)”。 (Johan De Gelas原著 双木译) |
| 下载本期推荐软件 | 页 首 |
| 《电脑报》版权所有,电脑报网站编辑部设计制作发布 |